科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2019-09-15
来源:BioArt
二十世纪以来,随着互联网和人工智能等信息技术的快速发展,使得信息量呈指数级飞快增长,据统计,全球数据信息总量将由2018年的30 ZB增长至2025年的163 ZB【1】。毫无疑问,我们已经进入信息大爆炸时代,我们或许很快就会生产出远超我们存储能力的更多数据,而现阶段人们大量使用的便携式硬盘、USB闪存和集成电路等存储体系已逐渐暴露出存储期限短、数据易受环境因素影响、生产设备耗能以及污染环境等不足【2,3】,因此,我们亟需寻找一种新的数据存储介质。
脱氧核糖核酸(DNA)作为已知的最密集、稳定的数据存储介质之一,具有密度大、能耗低、无磨损和寿命长等潜在优势,此外,DNA与信息存储之间有着很多相似之处,包括:1)均按一定顺序编码存储信息;2)均用符号注明信息段的起始点与终止点;3)均引入纠错码确保信息的完整性等等。基于以上特点,基于DNA的数据存储应运而生。
概括来说,DNA存储技术是指用人工合成的脱氧核苷酸链对文档、图片和音频等信息进行存储并能完整读取的技术。DNA是由4种碱基——腺嘌呤(A)和胸腺嘧啶(T)、鸟嘌呤(G)和胞嘧啶(C)按照碱基互补配对的特定顺序排列构成的双链分子,作为遗传信息指导生物体生长发育。而DNA存储技术就是在这4个碱基“字母”的基础上,开发区别于生物体的“语言”代码。储存数据时先将数据编码成二进制的数字串,然后用DNA中的碱基A、T、C、G编码二进制相对应的数字,使得数据以DNA链的形式完成目标DNA分子的构建(图1),再通过人工合成相应的DNA分子,数据即被储存在DNA分子中。读取数据时只需对目标DNA进行测序,还原为二进制格式的数字串,再完成解码工作即可【4】。对于DNA储存来说,数据写入即是人工合成DNA,数据读取即是DNA测序,数据的拷贝即是DNA的复制。
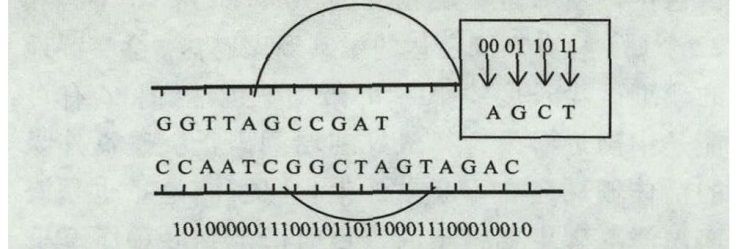
图1 数字信息的DNA分子构建【4】
DNA数据存储技术是生物技术与信息处理技术共同发展的结果,,它开辟了一种新的存储模式,其发展对于节省存储能源及推进大数据存储发展有着重要作用,对其研究也逐渐成为全球热点。微软在2016年就曾宣布,它和华盛顿大学研究人员合作,利用DNA数据存储技术保存了大约200MB数据,其中包括《战争与和平》和另外99部经典文学作品、被译成100多种语言的《世界人权宣言》、数字图书馆“古腾堡工程”排名前100位的电子书等【5】,这是DNA数据存储技术研究史上第一次一次性向DNA写入如此多数据,而微软也已计划于2020年在数据中心建立基于DNA的数据存储系统。
虽然近几年DNA存储得到了较大的发展,但现阶段DNA存储并未实现大规模使用,主要原因在于其存在成本高、耗时长且技术难点多,包括数据的检索与读取,特别是对大型数据库的随机访问容易出错等问题。
2019年9月9日,来自以色列理工学院的Zohar Yakhini教授研究团队在Nature Biotechnology发表题为Data storage in DNA with fewer synthesis cyclesusing composite DNA letters的文章,利用复合的DNA碱基“字母”进行编码,建立一个完整的大规模的基于DNA的存储系统,从而减少了数据编码的合成循环数,同时描述了适用的错误修正码和推理方法,并研究了复合DNA字母背景下的错误模式,使得DNA存储技术的发展有了新突破。

通常而言,基于DNA的存储系统的效率可以用几个定量指标来评估。其一是存储介质的物理密度,由每克DNA的数据单位来测量;另一个性能指标是一个数据单元所需的合成周期数,即逻辑密度,后者也是本文中主要关注的。
本文采用复合DNA字母编码方式来增加DNA存储的逻辑密度,使之突破传统的严格的单分子理论限制,即每个合成周期2个字节。这种复合DNA字母代表了序列中的某个位置,该序列由全部四种标准DNA核苷酸(A、C、G、T)按指定的预定比例σ混合而成,其中σ=(σA,σC,σG,σT),同时用κ=σA+σC+σG+σT代表复合字母的分辨率参数。在DNA序列的给定位置写入一个复合DNA字母相当于产生(合成)序列的多个拷贝(寡核苷酸),以至于在这个给定位置,不同的DNA核苷酸可以按照给定的σ分布于合成的拷贝上。而阅读一个复合字母需要对代表同一复合序列的多个独立分子进行排序,并根据观察到的碱基频率推断出原始比率或成分(图2)。

图2 利用标准DNA字母(a)和复合DNA字母(b)编码二进制信息
本文研究人员首先建立了一个基于6个字母的复合字母表的大规模存储系统,结合合适的Reed Solomon错误修正码,成功储存并恢复了2.12MB的数据,从而证明了复合DNA字母表概念的可行性,并展示了其改进基于DNA的数据存档系统的潜力。
进一步的,研究人员使用不同的组合中位数将6.4MB的数据编码到合成DNA中,与之前的研究相比,每字节数据使用的合成周期减少了20%。同时,研究人员还模拟了使用更大的组合字母和可区分的组合十分位数进行编码,结果表明合成周期减少75%也是可以实现的。考虑到DNA合成成本与合成周期的总数密切相关,因此复合DNA字母的使用对于逻辑密度的增加很有可能降低DNA存储的成本。
尽管复合DNA字母的应用使得基于DNA的数据存储利用了更少的DNA合成循环,但是,该优势也影响了DNA存储系统效率的其他性能指标,因此要将其纳入未来基于DNA的存储系统的发展仍将需要在以下几个方面进行进一步的研究和投资。首先也是最重要的是,本文研究证实复合DNA字母的应用影响了所需的测序深度和物理密度,因此任何大规模的实现都需要扩大目前有限的合成复合DNA的商业硬件设施;第二,使用高度复用的复合DNA序列将需要更好地了解复合DNA对DNA操作中涉及的不同化学过程的影响;第三,复合DNA序列或相关编码方法的设计原则,以及解码路径,可以进一步调整以获得最佳的结果。
综上所述,本文的研究和建议的方法论将复合DNA核苷酸的应用潜力添加到基于DNA的数据存储中,这将有望为进一步研究和开发高效的复合DNA合成技术做出贡献,而这一技术为DNA存储技术的发展提出了新的方向,其也可以应用于所有相关应用中。
原文链接:
https://doi.org/10.1038/s41587-019-0240-x
参考文献
1. ZHIRNOV V,ZADEGAN R M, SANDHU G S, et al. Nucleic Acid Memory[J].Nature Materials, 2016,15 (4) :366-370.
2. GODA K,KITSUREGAWA M. The History of Storage Systems[J].Proceedings of the IEEE, 2012,100 (13) :1433-1440.
3. GODA K,KITSUREGAWA M.The History of Storage Sys- tems[J].Proceedings of theIEEE, 2012,100 (13) :1433-1440.
4. 周谷成,范艳艳,肖义军. DNA存储技术的研究概述[J].生物学通.2018,53(08),10-12.
5. 张淑芳,彭康,宋香明等. DNA数据存储技术研究进展[J].计算机科学.2019,46(06),21-28.
来源:BioGossip BioArt
原文链接:https://mp.weixin.qq.com/s?__biz=MzA3MzQyNjY1MQ==&mid=2652475294&idx=2&sn=26abfb73a30e2b3149ee0af2e63fe8e8&chksm=84e21c2ab395953c7bcab939da2e6e8fd64a9d8c3e9658151a4eee676abd6039773e3de1f54e&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
【大师讲堂】解读生命密码:DNA的复制历程
【大师讲堂】解读生命密码:DNA的复制历程

全球首款“蚕丝硬盘”问世!可植入人体,可存储DNA

全球首款“蚕丝硬盘”问世!可植入人体,可存储DNA
合成生物学: 一个用来控制转基因生物的内置毁灭开关

科学家首次揭开DNA复制的秘密

DNA复制体结构和工作原理首次被揭示

全球首款“蚕丝硬盘”问世!可植入人体,可存储DNA

大数据环境下的智能存储技术
王艳丽:做研究就像破案


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号