科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-10-21
来源:PaperWeekly
在当前的 NLP 领域,Transformer / BERT 已然成为基础应用,而 Self-Attention 则是两者的核心部分,下面尝试用 Q&A 和源码的形式深入 Self-Attention 的细节。
Q&A
1. Self-Attention 的核心是什么?
Self-Attention 的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
2. Self-Attention 的时间复杂度是怎么计算的?
Self-Attention 时间复杂度:,这里,n 是序列的长度,d 是 embedding 的维度,不考虑 batch 维。
Self-Attention 包括三个步骤:相似度计算,softmax 和加权平均。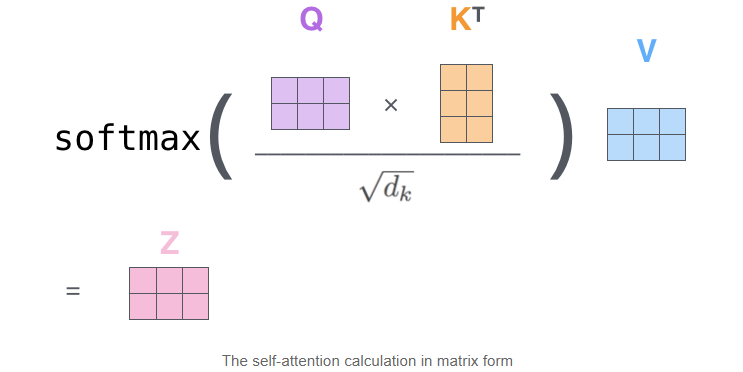
它们分别的时间复杂度是:
相似度计算 可以看作大小为 和 的两个矩阵相乘:,得到一个 的矩阵。
softmax 就是直接计算了,时间复杂度为 。
加权平均 可以看作大小为 和 的两个矩阵相乘:,得到一个 的矩阵。
因此,Self-Attention 的时间复杂度是 。
这里再提一下 Tansformer 中的 Multi-Head Attention,多头 Attention,简单来说就是多个 Self-Attention 的组合,它的作用类似于 CNN 中的多核。
多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。
In practice, the multi-headed attention are done with transposes and reshapes rather than actual separate tensors. —— 来自 google BERT 源代码注释
Transformer/BERT 中把 d ,也就是 hidden_size/embedding_size 这个维度做了 reshape 拆分,可以去看 Google 的 TF 源码或者上面的 pytorch 源码:
hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a。
并将 num_attention_heads 维度 transpose 到前面,使得 Q 和 K 的维度都是 (m,n,a),这里不考虑 batch 维度。
这样点积可以看作大小为 (m,n,a) 和 (m,a,n) 的两个张量相乘,得到一个 (m,n,n) 的矩阵,其实就相当于 m 个头,时间复杂度是 。
张量乘法时间复杂度分析参见:矩阵、张量乘法的时间复杂度分析 [1]。
因此 Multi-Head Attention 时间复杂度就是 ,而实际上,张量乘法可以加速,因此实际复杂度会更低一些。
3. 不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会怎么样?
对于 Attention 机制,都可以用统一的 query/key/value 模式去解释,而对于 self-attention,一般会说它的 q=k=v,这里的相等实际上是指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了 QKV 参数矩阵的。那如果不乘,每个词对应的 q,k,v 就是完全一样的。
在 self-attention 中,sequence 中的每个词都会和 sequence 中的每个词做点积去计算相似度,也包括这个词本身。
在相同量级的情况下,qi 与 ki 点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
那在 softmax 后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
而乘以 QKV 参数矩阵,会使得每个词的 q,k,v 都不一样,能很大程度上减轻上述的影响。
当然,QKV 参数矩阵也使得多头,类似于 CNN 中的多核,去捕捉更丰富的特征/信息成为可能。
4. 在常规 attention 中,一般有 k=v,那 self-attention 可以嘛?
self-attention 实际只是 attention 中的一种特殊情况,因此 k=v 是没有问题的,也即 K,V 参数矩阵相同。
扩展到 Multi-Head Attention 中,乘以 Q、K 参数矩阵之后,其实就已经保证了多头之间的差异性了,在 q 和 k 点积 +softmax 得到相似度之后,从常规 attention 的角度,觉得再去乘以和 k 相等的 v 会更合理一些。
在 Transformer / BERT 中,完全独立的 QKV 参数矩阵,可以扩大模型的容量和表达能力。
但采用 Q,K=V 这样的参数模式,我认为也是没有问题的,也能减少模型的参数,又不影响多头的实现。
当然,上述想法并没有做过实验,为个人观点,仅供参考。
源码
在整个 Transformer / BERT 的代码中,(Multi-Head Scaled Dot-Product) Self-Attention 的部分是相对最复杂的,也是 Transformer / BERT 的精髓所在,这里给出 Pytorch 版本的实现 [2],并对重要的代码加上了注释和维度说明。
话不多说,都在代码里,它主要有三个部分:
初始化:包括有几个头,每个头的大小,并初始化 QKV 三个参数矩阵。
来源:paperweekly PaperWeekly
原文链接:https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247513086&idx=2&sn=e4032cc09b00c5bdbe9706094fe70414&chksm=96ea6c7ea19de568e8a42397e1b5a10faf10f43a436e3595db6dc75939ad9bffbceaf9d736a8#rd
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
时间复杂度

Attention!注意力机制模型最新综述
微软亚研:对深度神经网络中空间注意力机制的经验性研究



AAAI 2019 | 选择型阅读理解问题上的空间卷积Attention模型

Attention!2019世界工业设计大会日程来了

NAACL 2019论文独特视角|纠正归因谬误:注意力没有解释模型

科学家证明量子复杂度在长时间内呈指数级线性增长

Attention最新进展

Attention注意力机制的前世今身


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号