

孙熙宸
加好友
孙熙宸 2019-11-13
来源:电力系统自动化
该文为国家重点研发计划项目成果。2019年9月发表于MPCE第7卷第5期。
引文信息:
Yi WANG, Dahua GAN, Ning ZHANG, et al. Feature selection for probabilistic load forecasting via sparse penalized quantile regression[J]. Journal of Modern Power Systems and Clean Energy, 2019, 7(5): 1200-1209
Feature selection for probabilistic load forecasting via sparse penalized quantile regression
基于稀疏惩罚的概率性负荷预测特征选择方法
DOI: 10.1007/s40565-019-0552-3
作者:王毅,甘达华,张宁,谢乐,康重庆
负荷预测是包含数据预处理、特征工程、模型建立与优化、结果分析与可视化等一系列环节的完整流程。目前大部分与负荷预测相关的文献都集中在预测模型的建立与优化上,少有研究关注负荷预测中的数据预处理和特征工程,特别是在概率预测领域。特征选择作为特征工程的重要组成部分,通过多种方法对原始数据进行分析、加工、提取,并选择出与预测模型最相关的特征,往往能够增强负荷预测的准确度,增加预测模型的可解释性,同时在原始数据过于复杂时,还可以降低模型的求解难度。
1
考虑临近效应的线性预测模型
以往电力系统的研究人员在建立负荷预测模型时,仅将当前时刻的天气信息(如温度)作为影响变量来对当前时刻的负荷进行估计。而研究人员发现,温度等天气信息对于负荷的影响往往具有滞后效应,即当前时刻的温度往往会影响若干小时之后的负荷水平。原因在于电力系统中的负荷需求和一些外部影响因素,本身就是滞后的。比如在某时刻气温突然上升,系统中的用户往往并不会立刻做出响应,而是在数分钟或数小时之后才采取降温措施,如打开空调等,从而使得负荷序列相对于温度序列是滞后的。因此,有文献提出一种考虑临近效应(Recency Effect)的多元线性回归模型,将历史温度的动平均值(Moving Average Temperature)和滞后温度(Lagged Temperature),以及其与时间变量的交互作用考虑到回归模型中,显著增加了模型预测的精准性。该模型由于存在大量的交叉相乘项,所以回归变量一般在几百个甚至上千个,而变量过多存在过拟合的风险,于是需要进行特征选择,提升预测模型的稳定性和鲁棒性。
2
基于pre-LASSO的线性概率预测模型的特征选择方法
目前绝大多数特征选择的研究都集中在传统的点预测领域,概率预测领域的特征选择仍然没有建立起相对完整的体系。LASSO (least absolute shrinkage and selection operator)是一种最为常用的特征选择方法,它是一种压缩估计方法,通过在多元线性回归模型的基础上叠加回归系数的L1 惩罚项,使优化过程中某些回归系数变为0,而取值为0的对应变量就会被过滤掉,从而实现对特征的选择。
如果先利用LASSO对点预测模型进行特征选择,则可将选择后的特征作为概率预测模型的输入。这是一种间接的特征选择方法,即利用LASSO进行特征选择是在训练概率预测模型之前进行,故将本方法称为pre-LASSO。pre-LASSO 方法是先依据点预测的临近效应模型使用LASSO做特征选择,再将特征送入预测模型,本质上并没有改变预测模型,因此理论上可以适用于任何概率预测模型。
3
基于概率预测模型的特征选择方法
本文提出的特征选择方法,是通过改变概率预测模型本身,使得概率预测模型具有特征选择的功能,不同模型之间不具有通用性,故称该方法为基于概率预测模型的特征选择方法。基于L1 惩罚的分位数回归模型,其本质就是给分位数回归模型的优化目标增加L1 惩罚项,使得原有的概率预测模型具有变量筛选的特性。该模型的优化目标如下:
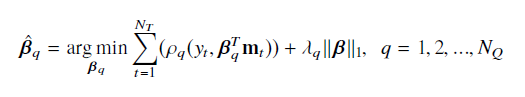
对于不同的分位数, λq的取值不同,这就意味着对变量选择的控制强度不同,从而可能出现不同分位数下,被选择下来的特征数量不尽相同的情况。这种方式相比于pre-LASSO,更增加了一种自由度,因为pre-LASSO 方法仅有一个调整参数控制特征选择的强度。通过算例结果的分析,我们会发现这种自由度的增加能对最终的预测效果带来更大的增益。
基于L1 惩罚的分位数回归模型的优化目标无法通过简单的引入辅助变量方式转变成常规的凸优化问题,因此,需要借助更强大的优化手段来对其进行求解,本文提出基于交替方向乘子法(ADMM)的模型优化方法,将上述模型转化为两个凸优化问题迭代求解,具体求解过程可参见原文。
4
本文提出方法的概率预测效果
本文所使用的算例数据为2012 年全球能源预测竞赛(2012 Global Energy Forecasting Competition,2012 GEFCom)的公开数据集。数据集包括美国北卡罗来纳州20 个地区2005—2008 年的电力系统小时负荷与和负荷对应的中长期温度预测值。我们选择2005—2007年的数据作为训练集,2008上半年的数据作为验证集,2008 下半年的数据作为测试集。
表1 不同特征选择方法的概率预测结果对比(分位数损失)
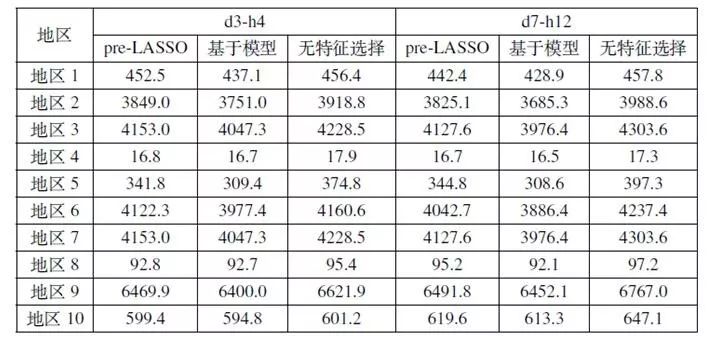
表1给出了3种方法在公开负荷数据集上10个地区的测试结果。可以看到无论是d3-h4方法还是d7-h12的临近模型,两种特征选择方法均比无特征选择时的分位数低,即概率预测结果要好。而对比两种方法,基于模型的特征选择方法比pre-LASSO方法具有更好的效果,这也印证了前面对于两种方法的对比分析,即基于模型的特征选择方法具有更大的自由度,因此可以分别优化不同分位数下的特征选择结果,从而在结果上超过pre-LASSO。
来源:AEPS-1977 电力系统自动化
原文链接:http://mp.weixin.qq.com/s?__biz=MzAxODIyNDUxNQ==&mid=2652017827&idx=1&sn=df7654fec15b63d51fa6f49ca394c1a4&chksm=803fb04fb7483959255910d75bbbf0be85d201720321eaae6ddae1660ef109c0b7582dc4d12d&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
Lasso算法
科学家开发出改进的混合多步风速预测模型



新模型精准预测土壤“碳排放”

新数学模型可预测游客度假地
语言模型可预测突变识别疫苗有效目标

模型越简单,越能准确预测某些气候风险

“过热”的气候预测模型可信吗
最新运算模型可高效预测电池性能

FRP-钢复合圆管约束混凝土轴压性能预测模型
新研究:预测耀斑的新物理模型
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号