科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2021-01-04
来源:量子位
不仅讲故事的本职工作做得风生水起,还跨界玩起了网页设计、运维、下象棋……不过,尽管表现惊艳,GPT-3背后到底是实实在在的1750亿参数,想要在实际应用场景中落地,难度着实不小。
现在,针对这个问题,普林斯顿的陈丹琦、高天宇师徒和MIT博士生Adam Fisch在最新论文中提出,使用较小的语言模型,并用少量样本来微调语言模型的权重。

并且,实验证明,这一名为LM-BFF(better few-shot fine-tuning fo language models)的方法相比于普通微调方法,性能最多可以提升30%。
方法原理
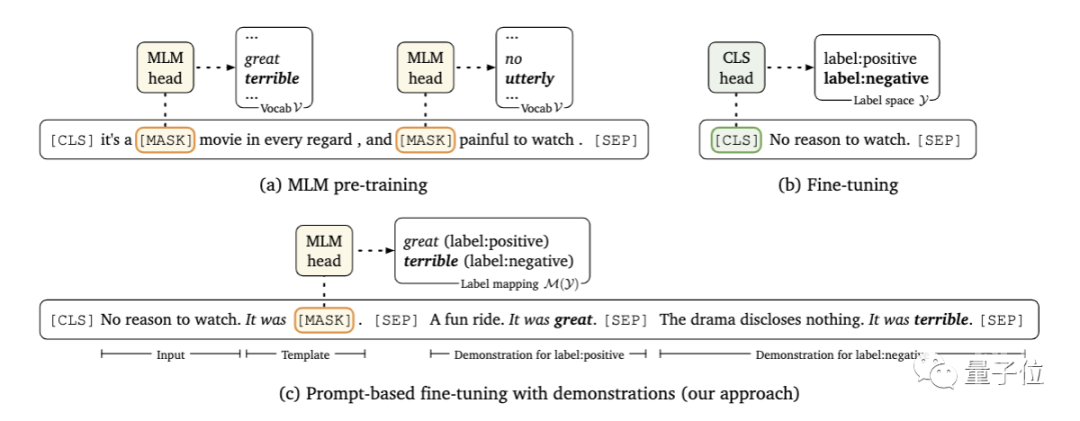
这里要解决的问题,是寻找正确的提示。这既需要该领域的专业知识,也需要对语言模型内部工作原理的理解。
在本文中,研究人员提出引入一个新的解码目标来解决这个问题,即使用谷歌提出的T5模型,在指定的小样本训练数据中自动生成提示。
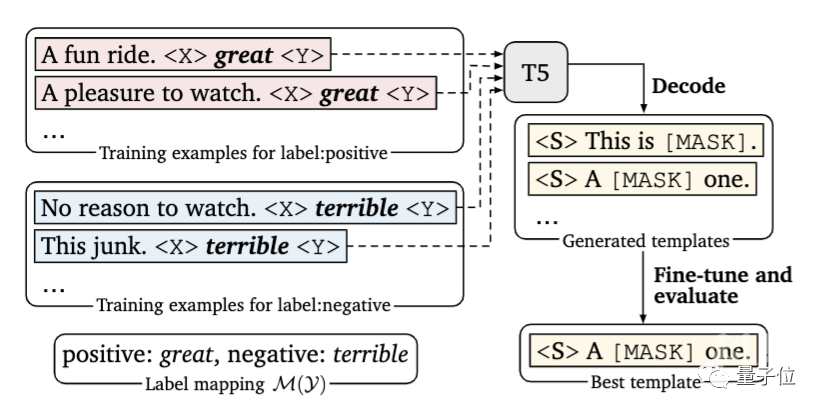
其次,研究人员在每个输入中,以额外上下文的形式添加了示例。
问题的关键在于,要有限考虑信息量大的示例,一方面,因为可用示例的数量会受到模型最大输入长度的限制;另一方面,不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
为此,研究人员开发了一种动态的、有选择性的精细策略:对于每个输入,从每一类中随机抽取一个样本,以创建多样化的最小演示集。
另外,研究人员还设计了一种新的抽样策略,将输入与相似的样本配对,以此为模型提供更多有价值的比较。
实验结果
那么,这样的小样本学习方法能实现怎样的效果?
研究人员在8个单句、7个句子对NLP任务上,对其进行了系统性评估,这些任务涵盖分类和回归。
结果显示:
基于提示的微调在很大程度上优于标准微调;
自动提示搜索能匹敌、甚至优于手动提示;
加入示例对于微调而言很有效,并提高了少样本学习的性能。
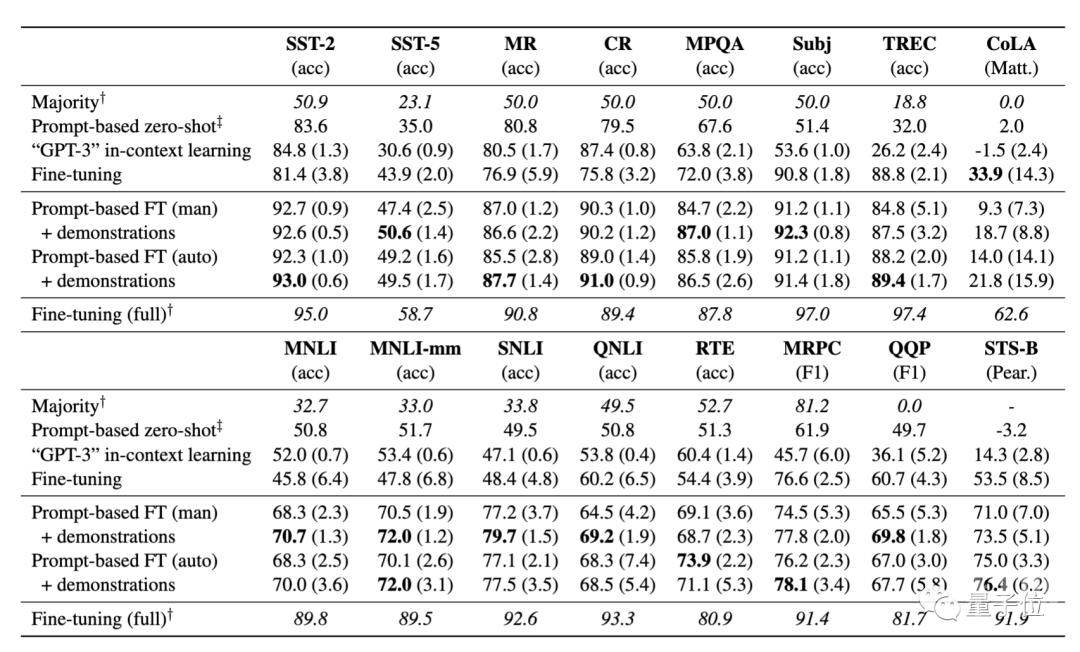
在K=16(即每一类样本数为16)的情况下,从上表结果可以看到,该方法在所有任务中,平均能实现11%的性能增益,显著优于标准微调程序。在SNLI任务中,提升达到30%。
不过,该方法目前仍存在明显的局限性,性能仍大大落后于采用大量样本训练获得的微调结果。
来源:QbitAI 量子位
原文链接:http://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247564779&idx=3&sn=13a924b25fdb1a1d7f9728d9a831427f
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
预训练语言模型fine-tuning近期进展概述

从对阵员决策角度看什么是兵棋推演?

基于语言模型的少样本学习

大语言模型对著名数学问题有“新见解”

基于预训练语言模型的文本生成研究综述

【前沿】MIT新开发的 AI 模型有望改进恶性脑瘤治疗
神经语言模型
Facebook AI Research的XLM模型:将BERT扩展成跨语言模型

CICC科普栏目|机器学习画布:一页纸把机器学习核心问题说清楚

CICC科普栏目|嘿嘿,想变成会跳舞的小哥哥或小姐姐吗?超简单!


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号