来源:机器之心
Transformer 的高性能依赖于极高的算力,这让移动端 NLP 严重受限。在不久之前的 ICLR 2020 论文中,MIT 与上海交大的研究人员提出了一种高效的移动端 NLP 架构 Lite Transformer,向在边缘设备上部署移动级 NLP 应用迈进了一大步。
虽然推出还不到 3 年,Transformer 已成为自然语言处理(NLP)领域里不可或缺的一环。然而这样流行的算法却需要极高的算力才能实现足够的性能,这对于受到算力和电池严格限制的移动端来说有些力不从心。
在 MIT 最近的研究《Lite Transformer with Long-Short Range Attention》中,MIT 与上海交大的研究人员提出了一种高效的移动端 NLP 架构 Lite Transformer,向在边缘设备上部署移动级 NLP 应用迈进了一大步。该论文已被人工智能顶会 ICLR 2020 收录。
该研究是由 MIT 电气工程和计算机科学系助理教授韩松领导的。韩松的研究广泛涉足深度学习和计算机体系结构,他提出的 Deep Compression 模型压缩技术曾获得 ICLR2016 最佳论文,论文 ESE 稀疏神经网络推理引擎 2017 年曾获得芯片领域顶级会议——FPGA 最佳论文奖,引领了世界深度学习加速研究,对业界影响深远。
Transformer 在自然语言处理任务(如机器翻译、问答)中应用广泛,但它需要大量计算去实现高性能,而这不适合受限于硬件资源和电池严格限制的移动应用。
这项研究提出了一种高效的移动端 NLP 架构——Lite Transformer,它有助于在边缘设备上部署移动 NLP 应用。其核心是长短距离注意力(Long-Short Range Attention,LSRA),其中一组注意力头(通过卷积)负责局部上下文建模,而另一组则(依靠注意力)执行长距离关系建模。
这样的专门化配置使得模型在三个语言任务上都比原版 transformer 有所提升,这三个任务分别是机器翻译、文本摘要和语言建模。
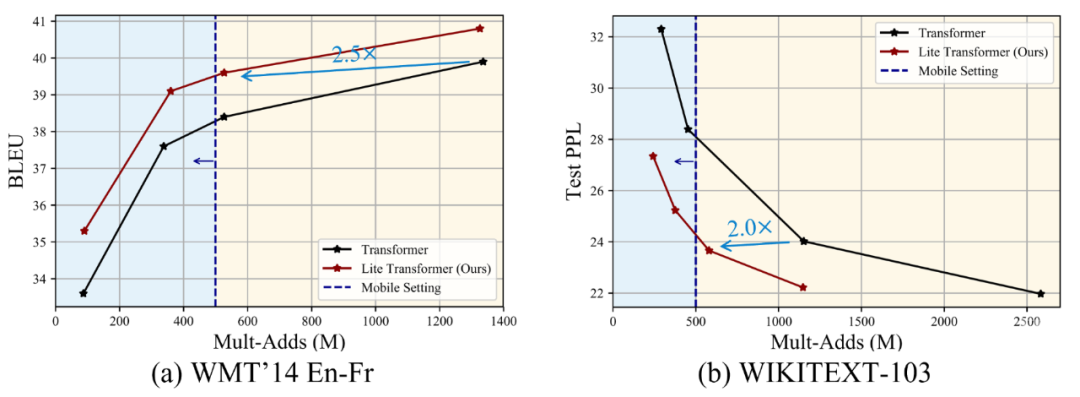
在资源有限的情况下(500M/100M MACs),Lite Transformer 在 WMT’14 英法数据集上的 BLEU 值比分别比 transformer 高 1.2/1.7。Lite Transformer 比 transformer base 模型的计算量减少了 60%,而 BLEU 分数却只降低了 0.3。结合剪枝和量化技术,研究者进一步将 Lite Transformer 模型的大小压缩到原来的 5%。
对于语言建模任务,在大约 500M MACs 上,Lite Transformer 比 transformer 的困惑度低 1.8。
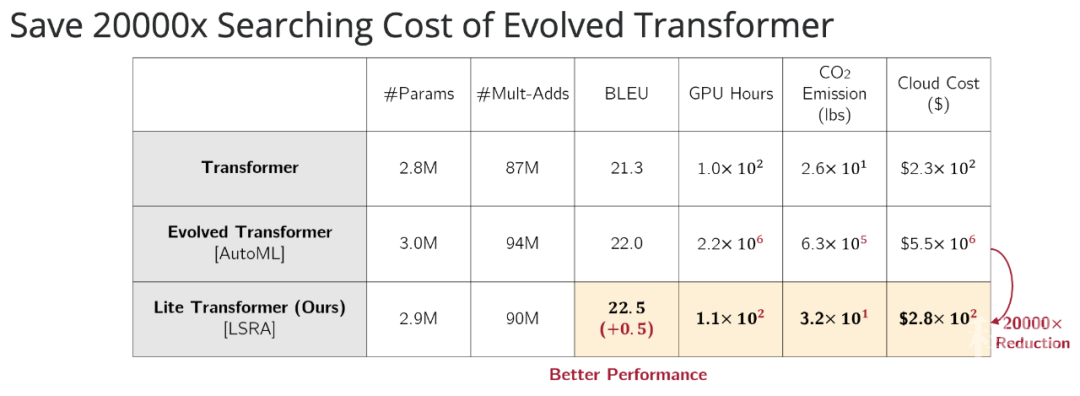
值得注意的是,对于移动 NLP 设置,Lite Transformer 的 BLEU 值比基于 AutoML 的 Evolved Transformer 高 0.5,而且它不需要使用成本高昂的架构搜索。
从 Lite Transformer 与 Evolved Transformer、原版 transformer 的比较结果中可以看出,Lite Transformer 的性能更佳,搜索成本相比 Evolved Transformer 大大减少。
那么,Lite Transformer 为何能够实现高性能和低成本呢?接下来我们来了解其核心思想。
长短距离注意力(LSRA)
NLP 领域的研究人员试图理解被注意力捕捉到的上下文。Kovaleva 等人 (2019) 和 Clark 等人 (2020) 对 BERT 不同层的注意力权重进行了可视化。
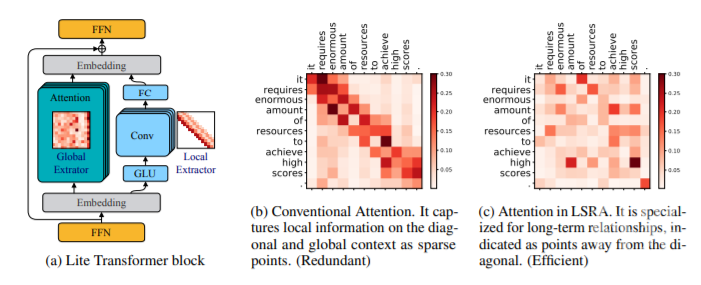
如下图 3b 所示,权重 w 表示源句单词与目标句单词之间的关系(自注意力也是如此)。随着权重 w_ij 的增加(颜色加深),源句中的第 i 个词更加注意目标句中的第 j 个词。注意力图通常有很强的模式化特征:稀疏和对角线。它们代表了一些特定单词之间的关系:稀疏表示长距离信息间的关系,对角线表示近距离信息间的关系。研究者将前者称为「全局」关系,将后者称为「局部」关系。
图 3:Lite Transformer 架构 (a) 和注意力权重的可视化。传统的注意力 (b) 过于强调局部关系建模(参见对角线结构)。该研究使用卷积层专门处理局部特征提取工作,以高效建模局部信息,从而使注意力分支可以专门进行全局特征提取 (c)。
在翻译任务中,注意力模块必须捕获全局和局部上下文,这需要很大的容量。与专门化的设计相比,这并非最佳选择。以硬件设计为例,CPU 等通用硬件的效率比 FPGA 等专用硬件低。研究者认为应该分别捕捉全局和局部上下文。模型容量较大时,可以容忍冗余,甚至可以提供更好的性能。但是在移动应用上,由于计算和功率的限制,模型应该更加高效。因此,更需要专门化的上下文捕获。
为了解决该问题,该研究提出一个更专门化的架构,即长短距离注意力(LSRA),而不是使用处理 “一般” 信息的模块。该架构分别捕获局部和全局上下文。
如图 3a 所示,LSRA 模块遵循两分支设计。左侧注意力分支负责捕获全局上下文,右侧卷积分支则建模局部上下文。研究者没有将整个输入馈送到两个分支,而是将其沿通道维度分为两部分,然后由后面的 FFN 层进行混合。这种做法将整体计算量减少了 50%。
左侧分支是正常的注意力模块(Vaswani et al. (2017)),不过通道维度减少了一半。至于处理局部关系的右分支,一个自然的想法是对序列应用卷积。使用滑动窗口,模块可以轻松地覆盖对角线组。为了进一步减少计算量,研究者将普通卷积替换为轻量级的版本,该版本由线性层和深度卷积组成。通过这种方式,研究者将注意力模块和卷积模块并排放置,引导它们对句子进行全局和局部的不同角度处理,从而使架构从这种专门化设置中受益,并实现更高的效率。
实验设置
数据集和评估 研究者在机器翻译、文本摘要和语言建模三个任务上进行了实验和评估。
具体而言,机器翻译任务使用了三个基准数据集:IWSLT’14 德语 - 英语 (De-En)、WMT 英语 - 德语 (En-De)、WMT 英语 - 法语(En-Fr)。
文本摘要任务使用的是 CNN-DailyMail 数据集。
语言建模任务则在 WIKITEXT-103 数据集上进行。
架构
模型架构是基于序列到序列学习的编码器 - 解码器。在机器翻译任务中,针对 WMT 数据集,基线模型基于 Vaswani 等人提出的模型。对于 IWSLT 数据集,基线模型遵循 Wu 等人的设置。对于文本摘要任务,研究者采用了与 WMT 相同的模型。至于语言建模任务,模型与 Baevski & Auli (2019) 一致,但模型尺寸较小。
该研究提出的架构首先将 transformer base 模型中的 bottleneck 拉平,然后用 LSRA 替换自注意力。更具体地说,是使用两个专门的模块,一个注意力分支和一个卷积分支。
来源:almosthuman2014 机器之心
原文链接:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650789244&idx=3&sn=498864894b6e1d584a45017911ce233c&chksm=871a1102b06d98144d851133ead6bd4c69f90843d6ed5ef4ef46f56bfc3256d46f43f463b419#rd
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn








 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号