科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2019-07-12
来源:人工智能
记得要去欧服
AI 科技评论按:昨晚,暴雪联合 DeepMind 发出一则新闻,DeepMind 开发的星际 2 AI「AlphaStar」很快就会出现在星际 2 欧洲服务器上的 1v1 天梯比赛中。人类玩家们不仅会有机会匹配到它们、和它们展开标准的比赛,比赛结果也会像正常比赛一样影响自己的天梯分数。
在星际 2 上做科研实验正如人尽皆知的围棋 AI AlphaGo,DeepMind 喜欢的强化学习 AI 研究过程是在某个比赛(博弈)环境中进行技术探索,在新技术的辅助下让智能体从历史数据中学习、从自我博弈中学习,然后与人类高手比赛,评估 AI 的水准。樊麾、李世石、柯洁都光荣地成为了「人工智能测试高级工程师」。

在此次星际 2 AI「AlphaStar」的研究过程中,DeepMind 继续沿用这个思路,但这次他们更大胆一点,让大批不同水准的普通玩家参与到 AI 表现的评估中来,最终的比赛结果会写到论述星际 2 AI 科研项目的论文里,向期刊投稿。这就是暴雪和 DeepMind 联手把 AI 送上天梯比赛的最重要原因。
进入星际 2 游戏,在 1v1 比赛设置了允许接入 DeepMind(DeepMind opt-in)之后,参加 1v1 天梯比赛的玩家们就可能会遇到 AlphaStar。为了控制所有的比赛都尽量接近正常的人类 1v1 天梯比赛,以及减小不同比赛之间的差异,AlphaStar 会随机匹配到一部分玩家的天梯比赛中,并且 AI 会在游戏保持匿名,匹配到的玩家和星际 2 后台都无法知道哪些比赛是有 AlphaStar 参与的。不过,设置了允许接入 AI 之后,相信玩家们立即就会开始对匹配到 AI 对手产生期待,而且在比赛开始之后也可能很快就会发现自己的对手有一些不寻常之处。
 一月的比赛中,AlphaStar 会建造大量工人,快速建立资源优势(超过人类职业选手的 16 个或 18 个的上限)
一月的比赛中,AlphaStar 会建造大量工人,快速建立资源优势(超过人类职业选手的 16 个或 18 个的上限)

今年一月时 AlphaStar 就曾与人类职业选手比赛并取得了全胜。相比于当时的版本,此次更大规模测试的 AlphaStar 版本进行了一些改动,其中一些改动明显对人类有利:
一月的版本可以直接读取地图上所有的可见内容,不需要用操作切换视角,这次需要自己控制视角,和人类一样只能观察到视野内的单位,也只能在视野内移动单位;
一月的版本仅使用了神族,这次 AlphaStar 会使用人族、虫族、神族全部三个种族;
一月的版本在操作方面没有明确的性能限制,这次,在与人类职业选手共同商议后,对 AlphaStar 的平均每秒操作数、平均每分钟操作数(APM)、瞬时最高 APM 等一些方面都做了更严格的限制,减少操作方面相比人类的优势。
参与测试的 AlphaStar 都是从人类比赛 replay 和自我比赛中学习的,没有从与人类的对局中学习,同时 AlphaStar 的表现会在整个测试期间保持不变,不进行训练学习;这样得到的测试结果能直接反应 DeepMind 目前的技术水准到达了怎么样的水平。另一方面,作为 AlphaStar 技术方案的一大亮点,参与测试的 AlphaStar 也会是 AlphaStar 种群(AlphaStar league,详见下文)中的多个不同个体,匹配到的不同 AlphaStar 个体可能会有迥异的游戏表现。
AlphaStar 技术特点在今年一月 DeepMind 首次公开 AlphaStar 与人类职业选手的比赛结果时,AI 科技评论就结合 DeepMind 官方博客对 AlphaStar 的技术特点进行了报道。这里我们再把 AlphaStar 的技术特点总结如下:(详细可以参见文章)
模型结构 - AlphaStar 使用的是一个长序列建模模型,模型从游戏接口接收的数据是单位列表和这些单位的属性,经过神经网络计算后输出在游戏中执行的指令。这个神经网络的基础是 Transformer 网络,并且结合了一个深度 LSTM 网络核心、一个带有指针网络的自动回归策略头,以及一个中心化的评分基准。
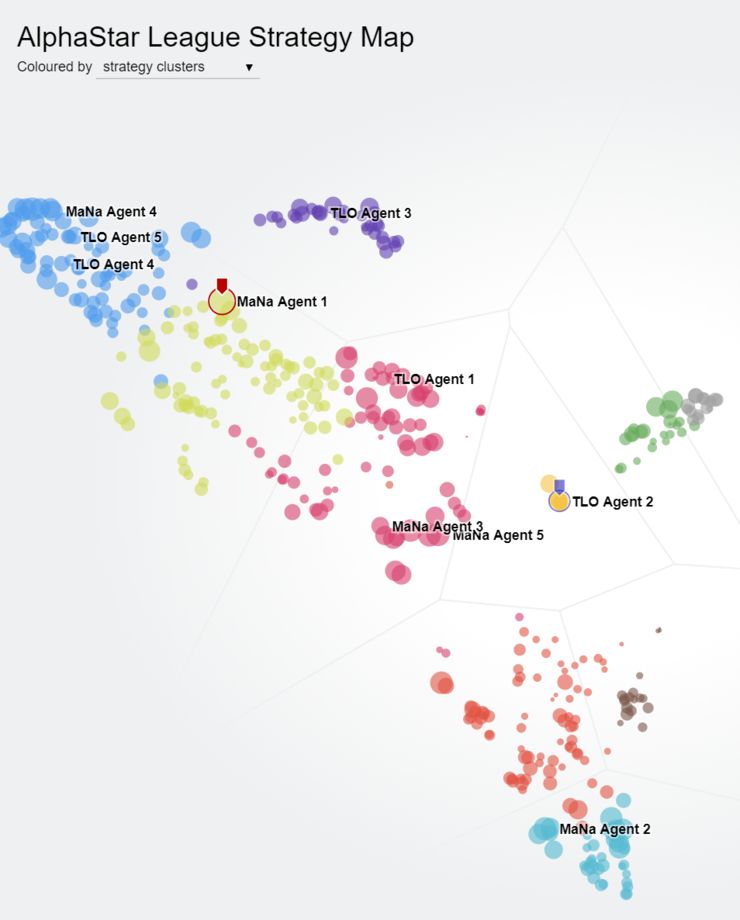
训练策略 - AlphaStar 首先根据高水平人类比赛进行监督学习训练(模仿学习),然后进行自我对弈。自我对弈的过程中使用了群体强化学习的思路:AlphaStar 自我对弈过程中始终都同时记录、更新多个不同版本的网络,保持一个群体,称作 AlphaStar league;AlphaStar league 中不同的网络具有不同的对战策略、学习目标等等,维持了群体的多样性,整个群体的对弈学习保证了持续稳定的表现提升,而且很新的版本也不会「忘记」如何击败很早的版本。
训练结果输出 - 当需要输出一个网络作为最终的训练结果时,以 AlphaStar league 中的纳什分布进行采样,可以得到已经发现的多种策略的综合最优解。
算力需求 - 为了支持大批不同版本 AlphaStar 智能体的对战与更新,DeepMind 专门构建了一个大规模可拓展的分布式训练环境,其中使用了最新的谷歌 TPUv3。AlphaStar league 的自我对战训练过程用了 14 天,每个 AlphaStar 智能体使用了 16 个 TPU,最终相当于每个智能体都有长达 200 年的游戏时间。训练结束后的模型在单块消费级 GPU 上就可以运行。
操作统计 - 在今年一月的版本中,AlphaStar 的平均 APM 为 280,峰值 APM 超过 1000,计算延时平均为 350 毫秒;切换关注区域的速度大约是每分钟 30 次。
此次在 AlphaStar 中测试的大行动空间下的长序列建模,以及群体强化学习的训练策略,都是对提升强化学习算法表现上限、应对复杂环境长期任务的积极技术探索。我们期待早日看到 DeepMind 的这篇论文成文,更早日看到基于强化学习的决策系统整个领域都发展得更成熟。当然了,喜欢星际 2 的读者,可以准备起来,为 DeepMind 的这篇论文贡献自己的一分力量吧!
来源:worldofai 人工智能
原文链接:http://mp.weixin.qq.com/s?__biz=MzAwNzIyMTQ2MA==&mid=2649695742&idx=1&sn=88f0a557df3e9c54be059ba88774f5dd&chksm=831afc45b46d75535f5d24fbab1780b2d6b7ef9fd9e12f1fb31ccf386658bb4f45b198a93d10&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn

Nature Video:AI的《星际争霸II》宗师之路

是游戏更是对未来战争的演练,从《星际争霸》看未来自主作战决策技术

前沿丨DeepMind最新论文:强化学习“足以”达到通用人工智能

专家说|人工智能与“星际争霸”:多智能体博弈研究新进展
Alphastar再登Nature!星际争霸任一种族,战网狂虐99.8%人类玩家

Deepmind 走在人工智能最前沿

“阿法星”在“星际争霸”中比肩顶尖人类玩家
谷歌AI五年拿下星际争霸II始末!两周搞定200年训练,人类毫无可比性
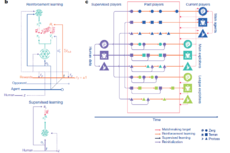
胜率99.8%,AlphaStar碾压星际争霸2人类玩家!《自然》刊发论文详解

公开反驳!数据科学家直指DeepMind,“强化学习无法实现通用人工智能”


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号