

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
实体关系识别是指在自然语言处理过程中抽取文本中实体间所隐含关系的任务。抽取的实体间关系可以通过不同形式的语言或形式表达,比如关系数据库、XML等等,其中RDF用来表示实体关系最为合理。
关系识别任务最早是在MUC7上正式提出的。一个简单的实体间关系例子如下,“A在B工作"一工”这个句子包含了两个实体:“A”以及“B”。它们之间有雇佣关系。
相关概念信息提取信息抽取是从文本(Document) 中抽取用户感兴趣的信息,并形成结构化(Structured)的数据。针对的文档类型可以是结构化数据(Structured Data)、半结构化数据(Semi-structured Data)或无结构数据(Un-structured Data)。结构化数据一般指带有严格格式信息的数据,如:数据库中的表格,以及XML数据等等。半结构化数据是指带有一定格式信息,但又不是很明确的数据,如网页、论文、邮件等。无结构数据主要指完全没有结构信息的自由文本(FreeText)。不同的信息抽取系统,由于处理的对象类型和特点不同,往往有较大的差异。1
信息抽取技术可以应用于多个领域,比如学术搜索、商品搜索、文本挖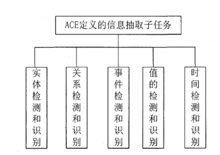 掘、知识库构建等等。由于信息抽取技术的广泛应用,信息抽取算法的研究越来越成为当前信息检索领域的热点。
掘、知识库构建等等。由于信息抽取技术的广泛应用,信息抽取算法的研究越来越成为当前信息检索领域的热点。
ACE会议定义的信息抽取任务是在单个文档内进行,不同的文档之间的抽取相互独立,不属于跨文档的信息抽取。年的会议所定义的子任务有:实体的检测和识别、关系的检测和识别、事件的检测与识别、值的检测和识别、时间的检测和识别。2
实体识别命名实体识别最初是在MUC6上作为一个子任务提出的。其中关注的实体类型主要包括组织名、人名、地名、时间表达式以及数值表达式等等。就识别的难度而言,时间表达式和数值表达式相对于其他的实体类型,识别相对简单,并能获得较好的精度。而对于组织机构名、地名和人名等类型,由于开放性和多样性的特点,识别过程较为困难。3
产生由来最早在1998年的第七届信息理解会议 (message understanding conference,MUC)上,首次提出了模板抽取的任务,这在后来发展成为关系抽取。在 MUC-7 会议上提出的关系抽取任务主要针对人物(persons)、地理位置(locations)和产品(artifacts)的模板类型,评测的语料内容主要来源于纽约时报对飞机事故和航天发射相关的新闻报道,并且设计了抽取结果的评价体系。
在1999年,美国国家技术研究院(National Institute of Standards and Technology,NIST)召开的自动内容抽取会议(automatic content extraction, ACE)取代了之前的 MUC 会议,并且对关系抽取评测的任务和训练材料进行了融合拓展和细化完善。在 2002 年,第三届会议正式加入了实体关系发现和识别任务(relation detection and recognition, RDR)。2008 年,ACE 会议正式将关系抽取任务划分为七种类型。2009 年,ACE 正式纳入文本分析会议(text analysis conference,TAC),成为知识库总体(knowledge base population, KBP)任务的重要组成部分。后期出现的语义评估(semantic evaluation,SemEval)会议SemEval-2007的评测任务4中设置了七种常用名词和名词短语间的实体关系,在SemEval-2010 评测任务8中将实体关系类型扩充到了10种。4
主要情况实体关系识别有三种情况:
(1)给定一种关系类型,自动识别具有该关系的两个命名实体;
(2)给定某一个实体和某种关系类型,自动识别具有该关系的另一实体;
(3)给定两个实体,自动判断两者是否具有某种关系类型。
研究现状关系抽取作为信息抽取中的重要子任务,国内前期的相关研究起步较晚,后期包括中国科学院、清华大学、北京大学等诸多科研院所在推动其研究发展上作出重要工作。在实现方式上,根据对于人工标注数据的依赖性可以细分为基于监督的方式、基于半监督的方式、无监督方式和面向开放域的抽取。后期又出现远程监督方式,深度学习逐渐火热和成熟之后也被应用到关系抽取之中,取得相比传统机器学习方法更加优秀的效果。接下来将分别对这些方法的研究进展进行详细的介绍。4
有监督的关系抽取基于监督的关系抽取以较高的准确率成为目前业界广泛应用的方式。其主要是利用分类的思想根据已有的人工标注数据进行模型的训练,然后进行特定关系的匹配识别和抽取工作。监督方式主要分为两大方法体系,分别是基于特征向量(feature-based)的方法和基于核函数(kernel-based)的方法。
基于特征向量的方法主要通过从句子上下文中提取出包括句法和语法等特征信息去构造特征向量,进而利用特征向量的相似度训练实体关系识别模型,完成实体关系识别和抽取。Kambhatla利用最大熵分类器构建抽取模型,通过加入文本特征,可以使用很少的词汇特征达到不错的效果,从而降低对于语义特征提取树的依赖,模型在 ACE RDC 2003 英文语料上的关系抽取的 F 值为 52.8%。很多基于特征向量的方法借助于传统机器学习实现,并且对特征的选取有很大增益。Giuliano 等人基于 SemEval-2007 的评测材料,通过实体上下文、距离等特征,借助支持向量机(support vector machine ,SVM)模型实现 71.8% F 值的抽取效果。Tratz 等人利用最大熵分类方法在 SemEval-2010 评测语料上实现抽取效果 F 值为 77.57%。Culotta 等人使用条件随机场的分类方法借助带有默认正则化参数的 MALLET CRF 实现关系抽取,取得了不错的效果。
虽然基于特征向量的抽取方法效果良好,但是作为模型基础的特征在选择和设置上更多依靠构建者的直觉和经验,并且对于上下文信息利用不足,于是需要提出可以较好地利用语料中的长距离特征和结构化特征的函数方法,在这一层面进行了弥补。Zelenko 等人引入基于核函数的关系抽取方法,通过核函数实现从低维向高维空间的映射,从而可以将非线性问题作为线性问题处理。Zelenko 等人提出使用浅层解析树核结合支持向量机从文本中提取人—隶属关系和组织—位置关系。Culotta 等人使用依存树核对新闻文章自动内容抽取(ACE)语料库中实体之间的关系进行了检测和分类,并且测试了词性和实体类型不同特性的效用,证实依赖树内核比“词袋”核实现了 20% F1 的改进。Bunescu 等人观察到依赖关系图中两个实体之间的最短路径可查找到实体关系,所以利用最短依存树核进行改进。Zhang 等人提出基于解析树的卷积核对句法结构信息建模,实现关系提取的方法。庄成龙等人通过在原关系实例的结构化信息中增添实体语义信息并筛除冗余信息的方法来提高关系抽取的性能,在 ACE RDC 2004 基准语料上进行的关系检测,F 值达到了 79.1%。总体上,基于核函数的方法由于匹配计算时的较强约束容易出现召回率较低的现象,并且模型训练和预测的时间复杂度较高。4
半监督的关系抽取半监督的关系抽取方法的主要思想是根据预先设计好的关系类型,通过人工添加合适的实体对作为种子。利用模式学习方法进行不断迭代学习,最终生成关系数据集和序列模式,在一定程度上降低了对于人工标注语料的依赖。
最常用途径是基于 Bootstrapping 方法实现。这是由Brin首先应用在关系抽取任务中,并建立了 DIPRE 系统,他以少量的书名及作者名作为种子实体关系对,从文档和语句中抽取新的实例并作为标注样本,根据标注样本建立新的抽取模板。利用建立的模板发现新的实体对关系并加入其中,期间不断调整和迭代。Agichtein 等人设计的 Snowball 方法是在其基础上推出的,主要改进是使用向量表示实体及实体关系的元组,通过向量的相似度来发现和迭代增大标注样本。在每次迭代提取的过程中,模型在不受人工干预的情况下评估这些模式和元组的质量,并且只保留其中最可靠的部分以提升整体质量。陈锦秀等人利用图策略建立基于图的半监督抽取模型,实现关系抽取性能的提升。
半监督的方法降低了关系抽取对于人工标注数据的依赖性,只需要人工进行最初种子集的构造,但是对种子集的质量要求较高,并且建立和优化相对繁琐的模板对于最终的抽取效果至关重要。这种方式普遍存在噪声实例及模板引入问题,进而在不断迭代过程中造成语义漂移的现象;且此类方法虽准确率有所提高,但是召回率普遍不高。4
无监督的关系抽取无监督的方法属于一种自底向上的抽取方式,通过先抽取实体及关系,进行大规模的冗余语料聚类,再对聚类集合进行关系标注。Hasegawa 等人首次应用无监督方式进行关系抽取,通过设置重复出现阈值识别潜在语义关系并聚类,实现抽取结果 F 值达到 75%。Shinyama 等人基于多层级聚类的无监督方法,使用了 12 家主要在美国出版的报道文章进行实验。
Hassan 等人提出了一种基于大数据集冗余和图相互增强的无监督信息提取方法,并采用从语料库中的 POS n-gram 获取关系提取模式。但是由于采用 n-gram,这种模式只包含 POS 和实体类型标记,导致 n-gram 数量的组合激增。Gonzalez 等人提出一种新的基于概率聚类模型的无监督方式关系提取方法,该方法得到的 F1 值为 55.7。Rozenfeld 等人建立的 URIES 是一个 Web 关系提取系统,通过对目标关系及其属性的简短描述,从未标记的文本中进行模式提取。
无监督抽取方式虽然对人工标注的语料依赖性降低,并且多领域适应性强,领域迁移障碍小,特别在多领域知识杂糅的大规模文本中相比其他有监督和半监督方法更是优势明显。但是无监督方法总体上关系标注较为宽泛,因为缺乏必要的语料库,导致低频实例抽取率低,最终识别的准确率和召回率也一般不高,在抽取评价标准上也难以量化和统一。4
面向开放域的关系抽取面向开放域的关系抽取不限定关系类别和目标文本,在跨领域和后期扩充上具有无法比拟的优势。开放式关系抽取默认同一实体对都存在已知的关系,通过前后相邻的短语进行实体关系上的语义表达,借助外部大型实体知识库包括DBPedia、YAGO、FreeBase 和其他领域知识库,将置信度较高的实体关系与大规模的训练数据进行匹配对齐,以获得大量训练数据。 Etzioni 等人搭建 KnowItAll 模型,通过人工编写规则模板从 web 中进行无监督的、独立于领域和面向可伸缩的大量事实(如科学家或政治家的姓名)地自动化匹配。模型中每个规则由谓词、提取模式、约束和关键字组成,进而借助简单的语法分析抽取实体关系。 Banko 等 人通 过 构 建TextRunner 模型,从 Web 中抽取包含用户输入的特定谓词的元组,模型包括三个关键模块:自我监督学习器对输入的小语料库样本进行处理,输出分类器对候选提取置信度的标记;单通道提取器利用整个语料库从每个句子生成一个或多个候选元组,进而得到所有可能的元组,保留标记为可信的元组;冗余评估器依据文本中的冗余概率模型为每个保留的元组分配概率。整个过程不需要人工进行标注,降低工作量,但是依旧存在召回率不高的问题。4
应用远程监督方法的关系抽取后来的研究着力点主要集中在如何降低对于人工标注语料库的依赖性,增强领域迁移性上。Mintz 等人在文本处理中尝试借用远程监督方法,假设若文本中的实体对和知识库的实体对完全一致,就标注它们具有同样的关系。该方法通过对齐语料库和文本自动生成训练样例,从而提取特征训练分类器,降低对于人工标注材料的依赖;但是知识库中事先标注的实体关系是不完备的,所以过于简易和强烈的假设极易引入错误。远程监督方法主要通过知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
为了改善远程监督单标签过强假设的问题,Surdeanu 等人又进一步提出基于概率图模型的多标签多实例的抽取方式,并引入词袋(word bag)模型,通过提升标注级别,将原本实体对级的标注改变为对多词形成的词袋进行标注以降低错误率。5
基于深度学习的关系抽取以上方法都借助传统的自然语言处理工具,但是工具本身也是很容易引入错误,经过这些工具处理后的结果降低了接下来的算法性能。考虑到语音、图像和文本处理肌理的相通性,当深度学习方法在图像领域崭露头角时,很多人尝试引入深度学习方法到关系抽取中,发挥其在特征提取和自动学习上的优势,并且将 SemEval-2010 task 8 作为测试标准。
Socher 等人通过使用递归神经网络(recurrent neural networks,RNN)模型,在句法树的节点上设置向量和矩阵,对命题逻辑和自然语言中算子的含义学习,从而得到多种句法 类 型 和 不 同 长 度 短 语 和 句 子 的 向 量 化 表 示 。 模型在SemEval-2010 Task 8 数据库上实现 F 值为 82.2%的抽取效果。 Hashimoto 等人在网络分类器中加入词嵌入方法,从语料库中抽取出实体对上下文特征信息,基于同样的数据库实现小幅度提升。
递归神经网络关注于语义的结构信息,但为获得这一信息需要依赖于传统自然语言处理工具,传统自然语言处理(natural language processing,NLP)工具噪声引入的弊端再次显露。于是 Zeng 等人利用卷积神经网络(convolutional neural networks, CNN)提取词汇和句子的层次特征进行关系抽取,减少输入材料复杂的预先标记处理。Nguyen 等人在此工作的基础上向卷积层中加入了多尺寸的卷积核作为过滤器,以此提取更多的 N-Gram 特征,并且使用了位置向量,证实了多尺寸卷积神经网络在关系抽取中的有效性。
Lin 等人引入 PCNN(piecewise CNN),对传统卷积神经网络的池化层进行改进,通过两个实体位置将 feature map 分为三段进行池化,其目的是更好地捕获两个实体间的结构化信息,并使用注意力机制,通过建立句子级选择性注意神经模型减轻错误标签问题,最终 F 结果比基于多示例学习的机器学习方法高了 5 个百分点。 Zhou 等人使用BLSTM(bidirectional long-short term memory)对句子建模,并使用 word 级别的 attention 机制提升结果。万静等人利用双向 GRU 和 PCNN 方法实现实体结构和更多特征信息的提取,在 NYT 数据集上不错效果。
Cai 等人提出了基于最短依赖路径(shortest path dependence,SDP)的深度学习关系分类模型,称为双向递归卷积神经网络模型(BRCNN)。使用 SemEval-2010 Task 8数据集,在关系分类任务中,实现了 F 值高达 86.3%的抽取效果。 2017 年,Lin 等人又尝试通过扩展到多语言语料库上,利用多语言语料信息的互补性和一致性提升抽取性能,这在多语言共存的文档中效果显著。
但是以上的所有关系抽取方法都将其分解为实体抽取( named entity recognition , NER )和关系抽取 (relation extraction,RE)两个依次进行的步骤。这种分割忽略任务间的关系,容易产生冗余信息,于是端到端方式的联合抽取被提出。在同一个模型中抽取出实体及其之间关系类型,实现参数共享、同步优化,降低之前流水式抽取出现错误累积的可能性。Zheng 等人利用共享神经网络底层表达进行联合学习。Miwa 等人同样通过参数共享 NER 使用一个神经网络进行解码,在 RC 上加入了依存信息,根据依存树最短路径使用一个 BiLSTM 来进行关系分类。Li 等人提出了增量集束搜索算法的联合结构化抽取方式和利用全局特征的约束方法,在 ACE 语料上比传统的流水线方法 F 值提升了1.5%。Zheng 等人使用了更加高效的偏置目标函数和一种新的标注策略,把原来涉及到序列标注任务和分类任务的关系抽取完全变成了一个序列标注问题,通过一个端对端的神经网络模型直接得到关系实体三元组。6
关系抽取的挑战和趋势总体上,关系抽取在领域自适应性和召回率层面仍有提升空间。借助已有的知识库并挖掘深度学习语义表示和自主学习能力,自动从训练数据中学习分类特征、自主进行语料扩充,进而增强领域的迁移性,减少对于人工标注语料的依赖。因此弱监督包括远程监督方式应该是研究和应用的方向之一,但是目前远程监督的错误标注噪声引入问题一直存在,虽通过多标签多实例方式进行改善,但是仍有提升空间。
并且现阶段的关系抽取大多集中在词汇、语句级别的实体间关系,很少扩大到段落甚至篇章级别的关系抽取,但是大量的代词在文段中需要依靠上下文信息,甚至段落篇章级进行语义理解,指代词在语义上和名词实体的等价关系应充分利用。通过共指消解处理结果的引入,更好地进行实体之间等价关系和非等价关系的融合,也可以进一步推理出长文档或者多文档实体之间存在的间接和潜在关系,借助简单推理实现长距离关系抽取,进一步提升关系抽取的召回率。
现在关系抽取的主流方式是二元关系抽取,即使是多元实体关系仍将其作为二元实体关系进行处理。但是现实世界中实体之间的三元甚至多元关系广泛存在,将二元抽取方法延伸至多元抽取,发现潜在实体关系、多元实体关系、多层次关系将会对实际应用产生巨大影响。4
本词条内容贡献者为:
徐恒山 - 讲师 - 西北农林科技大学
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号