科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
特征缩放是用来统一资料中的自变项或特征范围的方法,在资料处理中,通常会被使用在资料前处理这个步骤。因为在原始的资料中,各变数的范围大不相同。
简介对于某些机器学习的算法,若没有做过标准化,目标函数会无法适当的运作。举例来说,多数的分类器利用两点间的距离计算两点的差异,若其中一 个特征具有非常广的范围,那两点间的差异就会被该特征左右,因此,所有的特征都该被标准化,这样才能大略的使各特征依比例影响距离。
特征缩放(Feature Scaling)是将不同特征的值量化到同一区间的方法,也是预处理中容易忽视的关键步骤之一。除了极少数算法(如决策树和随机森林)之外,大部分机器学习和优化算法采用特征缩放后会表现更优。
动机因为在原始的资料中,各变数的范围大不相同。对于某些机器学习的算法,若没有做过标准化,目标函数会无法适当的运作。举例来说,多数的分类器利用两点间的距离计算两点的差异,若其中一 个特征具有非常广的范围,那两点间的差异就会被该特征左右,因此,所有的特征都该被标准化,这样才能大略的使各特征依比例影响距离。
另外一个做特征缩放的理由是他能使加速梯度下降法的收敛。1
方法重新缩放最简单的方式是重新缩放特征的范围到[0, 1]或[-1, 1], 依据原始的资料选择目标范围,通式如下:
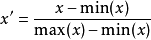
x 是原始的值, x' 是被标准化后的值。例如,假设我们有学生的体重资料,范围落在[160磅, 200磅],为了重新缩放这个资料,我们会先将每个学生的体重减掉160,接着除与40(最大体重与最小体重的差值)2
标准化在机器学习中,我们可能要处理不同种类的资料,例如,音讯和图片上的像素值,这些资料可能是高维度的,资料标准化后会使每个特征中的数值平均变为0(将每个特征的值都减掉原始资料中该特征的平均)、标准差变为1,这个方法被广泛的使用在许多机器学习算法中(例如:支持向量机、逻辑回归和类神经网络)。2
优点特征缩放可以使机器学习算法工作的更好。比如在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。因此每个特征应该被归一化,比如将取值范围处理为0到1之间。
特征缩放也可以加快梯度收敛的速度。1
应用在随机梯度下降法中, 特征缩放有时能加速其收敛速度。而在支持向量机中,他可以使其花费更少时间找到支持向量,特征缩放会改变支持向量机的结果。1
本词条内容贡献者为:
曹慧慧 - 副教授 - 中国矿业大学


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号