

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
算术编码是图像压缩的主要算法之一。 是一种无损数据压缩方法,也是一种熵编码的方法。和其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足(0.0 ≤ n 编码方法
若有一个a、b、c、d四种符号的单符号信源,待编序列为S=abda,已知: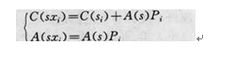
符号a b c d
符号概率Pi 0.100 0.010 0.001 0.001
(以二进位小数表示)
累积概率∑pi 0.000 0.100 0.110 0.111
按照一定精度的数值作为序列的算术编码,实质上是分割单位区间的过程。实现它,必须完成两个递推过程:一个代表码字C(·),另一个代表区间宽度为A(·)。若记SXi表示S的增长(即S后增加一个符号Xi)序列。则有图1 。
若记λ为空序列,有A(λ)=1,C(λ)=0,则有如图2 。
并依次求得:C(abd)= 010111, A(abd)= 0.00001
C(abda)= 0.010111 ,A(abda)= 0.000001 该编码过程可以用图3所示的单位区间划分的过程来描述。
译码为逆递推过程,可以通过对编码后的数值进行比较来实现。即判断C(S)落入哪一个区间,最后得出一个相应的符号序列S'=Ma=S。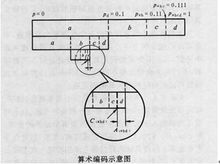
实际的编译码过程比较复杂,但原理相同,算术编码的理论性能也可使平均符号代码长度接近符号熵,而且对二元信源的编码实现比较简单,故受重视。中国将它应用于报纸传真的压缩设备中,获得了良好的效果。
工作原理在给定符号集和符号概率的情况下,算术编码可以给出接近最优的编码结果。使用算术编码的压缩算法通常先要对输入符号的概率进行估计,然后再编码。这个估计越准,编码结果就越接近最优的结果。
例: 对一个简单的信号源进行观察,得到的统计模型如下:
60% 的机会出现符号 中性
20% 的机会出现符号 阳性
10% 的机会出现符号 阴性
10% 的机会出现符号 数据结束符. (出现这个符号的意思是该信号源'内部中止',在进行数据压缩时这样的情况是很常见的。当第一次也是唯一的一次看到这个符号时,解码器就知道整个信号流都被解码完成了。)
算术编码可以处理的例子不止是这种只有四种符号的情况,更复杂的情况也可以处理,包括高阶的情况。所谓高阶的情况是指当前符号出现的概率受之前出现符号的影响,这时候之前出现的符号,也被称为上下文。比如在英文文档编码的时候,例如,在字母Q或者q出现之后,字母u出现的概率就大大提高了。这种模型还可以进行自适应的变化,即在某种上下文下出现的概率分布的估计随着每次这种上下文出现时的符号而自适应更新,从而更加符合实际的概率分布。不管编码器使用怎样的模型,解码器也必须使用同样的模型。
编码过程的每一步,除了最后一步,都是相同的。编码器通常需要考虑下面三种数据:
下一个要编码的符号
当前的区间(在编第一个符号之前,这个区间是[0,1), 但是之后每次编码区间都会变化)
编码器将当前的区间分成若干子区间,每个子区间的长度与当前上下文下可能出现的对应符号的概率成正比。当前要编码的符号对应的子区间成为在下一步编码中的初始区间。
例: 对于前面提出的4符号模型:
中性对应的区间是 [0, 0.6)
阳性对应的区间是 [0.6, 0.8)
阴性对应的区间是 [0.8, 0.9)
数据结束符对应的区间是 [0.9, 1)
当所有的符号都编码完毕,最终得到的结果区间即唯一的确定了已编码的符号序列。任何人使用该区间和使用的模型参数即可以解码重建得到该符号序列。
实际上我们并不需要传输最后的结果区间,实际上,我们只需要传输该区间中的一个小数即可。在实用中,只要传输足够的该小数足够的位数(不论几进制),以保证以这些位数开头的所有小数都位于结果区间就可以了。
**例: 下面对使用前面提到的4符号模型进行编码的一段信息进行解码。编码的结果是0.538(**为了容易理解,这里使用十进制而不是二进制;我们也假设我们得到的结果的位数恰好够我们解码。下面会讨论这两个问题)。
像编码器所作的那样我们从区间[0,1)开始,使用相同的模型,我们将它分成编码器所必需的四个子区间。分数0.538落在NEUTRAL坐在的子区间[0,0.6);这向我们提示编码器所读的第一个符号必然是NEUTRAL,这样我们就可以将它作为消息的第一个符号记下来。
然后我们将区间[0,0.6)分成子区间:
中性 的区间是 [0, 0.36) -- [0, 0.6) 的 60%
阳性 的区间是 [0.36, 0.48) -- [0, 0.6) 的 20%
阴性 的区间是 [0.48, 0.54) -- [0, 0.6) 的 10%
数据结束符 的区间是 [0.54, 0.6). -- [0, 0.6) 的 10%
我们的分数 .538 在 [0.48, 0.54) 区间;所以消息的第二个符号一定是NEGATIVE。
我们再一次将当前区间划分成子区间:
中性 的区间是 [0.48, 0.516)
阳性 的区间是 [0.516, 0.528)
阴性 的区间是 [0.528, 0.534)
数据结束符 的区间是 [0.534, 0.540).
我们的分数 .538 落在符号 END-OF-DATA 的区间;所以,这一定是下一个符号。由于它也是内部的结束符号,这也就意味着编码已经结束。(如果数据流没有内部结束,我们需要从其它的途径知道数据流在何处结束——否则我们将永远将解码进行下去,错误地将不属于实际编码生成的数据读进来。)
同样的消息能够使用同样短的分数来编码实现如 .534、.535、.536、.537或者是.539,这表明使用十进制而不是二进制会带来效率的降低。这是正确的是因为三位十进制数据能够表达的信息内容大约是9.966位;我们也能够将同样的信息使用二进制分数表示为.10001010(等同于0.5390625),它仅需8位。这稍稍大于信息内容本身或者消息的信息熵,大概是概率为0.6%的 7.361位信息熵。(注意最后一个0必须在二进制分数中表示,否则消息将会变得不确定起来。)
编码过程算术编码是用符号的概率和它的编码间隔两俩个基本参数来描述的(见下文教程)。算术编码可以是静态的或是自适应的。在静态算术编码中,信源符号的概率是固定的。在自适应算术编码中,信源符号的概率根据编码时符号出现的频繁程度动态地进行修改。2
在编码期间估算信源符号概率的过程叫建模。需要开发动态算术编码的原因,是因为事先知道精确的信源符号概率是很难的,而且是不切实际的。动态建模是确定编码器压缩效率的关键。
相关教程例如:
算术编码对某条信息的输出为 1010001111,那么它表示小数 0.1010001111,也即十进制数 0.64。
暂时使用十进制表示算法中出现的小数,这丝毫不会影响算法的可行性。
考虑某条信息中可能出现的字符仅有 a b c 三种,要压缩保存的信息为 bccb。
采用的是自适应模型,开始时暂时认为三者的出现概率相等,也就是都为 1/3,将 0 - 1 区间按照概率的比例分配给三个字符,即 a 从 0.0000 到 0.3333,b 从 0.3333 到 0.6667,c 从 0.6667 到 1.0000。用图形表示就是:
+-- 1.0000
|
Pc = 1/3 |
|
+-- 0.6667
|
Pb = 1/3 |
|
+-- 0.3333
|
Pa = 1/3 |
|
+-- 0.0000
现在拿到第一个字符 b,把目光投向 b 对应的区间 0.3333 - 0.6667。这时由于多了字符 b,三个字符的概率分布变成:Pa = 1/4,Pb = 2/4,Pc = 1/4。好,按照新的概率分布比例划分 0.3333 - 0.6667 这一区间,划分的结果可以用图形表示为:
+-- 0.6667
Pc = 1/4 |
+-- 0.5834
|
|
Pb = 2/4 |
|
|
+-- 0.4167
Pa = 1/4 |
+-- 0.3333
接着拿到字符 c,现在要关注上一步中得到的 c 的区间 0.5834 - 0.6667。新添了 c 以后,三个字符的概率分布变成 Pa = 1/5,Pb = 2/5,Pc = 2/5。用这个概率分布划分区间 0.5834 - 0.6667:
+-- 0.6667
|
Pc = 2/5 |
|
+-- 0.6334
|
Pb = 2/5 |
|
+-- 0.6001
Pa = 1/5 |
+-- 0.5834
现在输入下一个字符 c,三个字符的概率分布为:Pa = 1/6,Pb = 2/6,Pc = 3/6。来划分 c 的区间 0.6334 - 0.6667:
+-- 0.6667
|
|
Pc = 3/6 |
|
|
+-- 0.6501
|
Pb = 2/6 |
|
+-- 0.6390
Pa = 1/6 |
+-- 0.6334
输入最后一个字符 b,因为是最后一个字符,不用再做进一步的划分了,上一步中得到的 b 的区间为 0.6390 - 0.6501,好,在这个区间内随便选择一个容易变成二进制的数,例如 0.64,将它变成二进制 0.1010001111,去掉前面没有太多意义的 0 和小数点,我们可以输出 1010001111,这就是信息被压缩后的结果,就完成了一次最简单的算术压缩过程。
相关介绍精度再归一化上面对算术编码的解释进行了一些简化。尤其是,这种写法看起来好像算术编码首先使用无限精度精度的数值计算总体上表示最后节点的分数,然后在编码结束的时候将这个分数转换成最终的形式。许多算术编码器使用优先精度的数值计算,而不是尽量去模拟无限精度,因为它们知道解码器能够匹配、并且将所计算的分数在那个精度四舍五入到对应值。一个例子能够说明一个模型要将间隔[0,1]分成三份并且使用8位的精度来实现。注意既然精度已经知道,我们能用的二进制数值的范围也已经知道。
一个称为再归一化的过程使有限精度不再是能够编码的字符数目的限制。当范围减小到范围内的所有数值共享特定的数字时,那些数字就送到输出数据中。尽管计算机能够处理许多位数的精度,编码所用位数少于它们的精度,这样现存的数据进行左移,在右面添加新的数据位以尽量扩展能用的数据范围。注意这样的结果出现在前面三个例子中的两个里面。
美国专利许多算术编码所用的不同方法受美国专利的保护。其中一些专利对于实现一些国际标准中定义的算术编码算法是很关键的。在这种情况下,这些专利通常按照一种合理和非歧视(RAND)授权协议使用(至少是作为标准委员会的一种策略)。在一些著名的案例中(包括一些涉及 IBM的专利)这些授权是免费的,而在另外一些案例中,则收取一定的授权费用。RAND条款的授权协议不一定能够满足所有打算使用这项技术的用户,因为对于一个打算生产拥有所有权软件的公司来说这项费用是“合理的”,而对于自由软件和开源软件项目来说它是不合理的。
在算术编码领域做了很多开创性工作并拥有很多专利的一个著名公司是IBM。一些分析人士感到那种认为没有一种实用并且有效的算术编码能够在不触犯IBM和其它公司拥有的专利条件下实现只是数据压缩界中的一种持续的urban legend(尤其是当看到有效的算术编码已经使用了很长时间最初的专利开始到期)。然而,由于专利法没有提供“明确界线”测试所以一种威慑心理总让人担忧法庭将会找到触犯专利的特殊应用,并且随着对于专利范围的详细审查将会发现一个不好的裁决将带来很大的损失,这些技术的专利保护然而对它们的应用产生了一种阻止的效果。至少一种重要的压缩软件bzip2,出于对于专利状况的担心,故意停止了算术编码的使用而转向Huffman编码。
关于算术编码的美国专利列在下面。
Patent 4,122,440 — (IBM) 提交日期 March 4, 1977, 批准日期 Oct 24, 1978 (现在已经到期)
Patent 4,286,256 — (IBM) 批准日期 Aug 25, 1981 (大概已经到期)
Patent 4,467,317 — (IBM) 批准日期 Aug 21, 1984 (大概已经到期)
Patent 4,652,856 — (IBM) 批准日期 Feb 4, 1986 (大概已经到期)
Patent 4,891,643 — (IBM) 提交时间 1986/09/15, 批准日期 1990/01/02
Patent 4,905,297 — (IBM) 批准日期 Feb 27, 1990
Patent 4,933,883 — (IBM) 批准日期 Jun 12, 1990
Patent 4,935,882 — (IBM) 批准日期 Jun 19, 1990
Patent 4,989,000 — (???) 提交时间 1989/06/19, 批准日期 1991/01/29
Patent 5,099,440
Patent 5,272,478 — (Ricoh)
注意:这个列表没有囊括所有的专利。关于更多的专利信息请参见后面的链接。
算术编码的专利可能在其它国家司法领域存在,参见软件专利中关于软件在世界各地专利性的讨论。
本词条内容贡献者为:
孔祥杰 - 副教授 - 大连理工大学软件学院
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号