

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
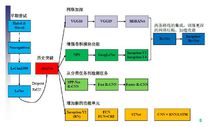
2012年AlexNet做出历史突破以来,直到GoogLeNet出来之前,主流的网络结构突破大致是网络更深(层数),但是纯粹的增大网络的缺点:1.参数太多,容易过拟合,若训练数据集有限;2.网络越大计算复杂度越大,难以应用;3.网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型。Inception就是在这样的情况下应运而生。
Inception结构简介自从2012年Krizhevsky等赢了ImageNet竞赛后,他们的AlexNet被成功应用在大量的计算机视觉任务,例如物体检测,分割,人体姿势估计,视频分类,物体追踪和图像超分辨。
这些成功激发了对于找到更好执行卷积神经网络的的研究。从2014年起,使用更深、更宽的网络大幅提高了网络结构的质量。VGGNet和GoogleNet在2014ILSVRC分类大赛中取得了相似的突出成绩。一个有意思的现象是在分类中表现突出的模型在很多领域都有广泛应用。这意味着深度视觉结构的提升可以用于提升大部分依赖高质量视觉特征的其它计算机视觉任务。同样,网络质量的提高引发了新的卷积网络应用,比如此前AlexNet特征还无法比拟的手工分辨率调整。
虽然VGGNet有吸引人的简单结构,相应的评估网络需要大量计算。另一方面GoogleNet的Inception结构也是设计用于在严格的内存和计算条件下执行。GoogleNet只使用500万个参数,是AlexNet的1/12,它使用了6000万个参数。VGGNet使用了比AlexNet3倍多的参数。
Inception的计算成本也低于VGGNet,这使它能够应用于大数据场景,或是在有限的内存和计算能力的情况下以相对合理的成本处理较大的数据,如移动端。当然我们可以通过计算技巧来优化一些特定的操作来解决该问题。但是这些方法加大了复杂性。另外,这些优化的方法也可以应用了Inception结构,扩大了效率差。
Inception结构的复杂性使它依然存在修改困难的问题。如果只是简单的扩大结构规模,计算的优势会马上消失。并且不能清楚的描述GoogLeNet结构不同设计的考虑因素。这使它难以在维持效率的同时依据新情况更新。例如,如果需要提高一些Inception风格模型的能力,简单的加倍过滤器大小会导致4倍增加计算成本和参数。这在很多实际场景中并不现实。这里,我们提出一些能够有效提高卷积网络规模的原则和优化建议。虽然我们的原则不仅限于Inception风格网络,他们更适应于Inception风格的灵活可兼容性。这通过大量使用Inception模块的降低维度和平行结构实现,减轻了结构变动对周边组件的影响。使用此种方式时依然要保持谨慎,不断观察以维持模型的高质量1。
设计原则1、避免表征瓶颈,特别是在网络早期。前向传播网络可以从输入层到分类器或回归器的无环图来体现。这定义了清晰的信息流。从每一个分割输入和输出的切入,能够获得通过这个切入的信息流量。应该避免使用极端压缩导致的瓶颈。一般讲表征规模应平缓的从输入向输出递减知道最终任务。理论上,信息内容无法仅通过表征的维度来评估,因为它舍弃了一些重要因素相关性结构;维度仅提供了信息内容的粗略估计。
2、更高维度的表征更容易在一个网络内本地化处理。在卷积网络中加大每层的激活能获得更多的非纠缠特征,可使网络训练更快速。
3、可以在更低维度嵌入上进行空间聚合,不会损失或损失太多的体现能力。例如在进行3*3卷积之前,可以在空间聚合之前降低输入表征,不会有严重问题。我们假设它是因为在空间聚合情况下使用输出,相邻单元结果的强相关性在降低维度时损失较小。基于此这些信号可便利的被压缩,并且维度降低能使学习更快。
4、平衡网络的宽度和深度。网络的优化表现可以通过平衡每阶段的过滤器数量和网络深度实现。同时提高宽度和深度可以提高网络质量,但是只有并行提高时才能对计算常量优化提升,因此要在网路的深度和宽度合理平衡分配计算能力1。
Inception V1模型Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性1。
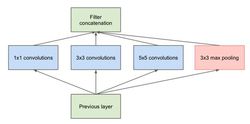
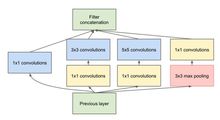
第一张图是最原始的版本,所有的卷积核都在上一层的所有输出上来做,5×5的卷积核所需的计算量就太大,造成了特征图厚度很大。为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低特征图厚度的作用,也就是Inception v1的网络结构。
 右图为GoogLeNet的结构图:
右图为GoogLeNet的结构图:
Inception v2模型一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯;
另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
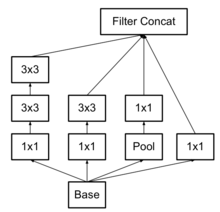
使用3×3的已经很小,那么更小的虽然能使得参数进一步降低,但是不如另一种方式更加有效,就是Asymmetric方式,即使用1×3和3×1两种来代替3×3的卷积核。这种结构在前几层效果不太好,但对特征图大小为12~20的中间层效果明显2。
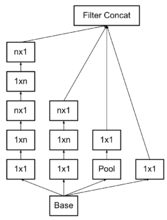
Inception v3模型V3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块3。
Inception v4模型v4研究了Inception模块结合Residual Connection能不能有改进。发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能4。
本词条内容贡献者为:
王慧维 - 副研究员 - 西南大学
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号