科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
siamese网络从数据中去学习一个相似性度量,用这个学习出来的度量去比较和匹配新的未知类别的样本。
Siamese结构的提出Siamese网络是一种相似性度量方法,当类别数多,但每个类别的样本数量少的情况下可用于类别的识别、分类等。由于每个类别的样本太少,我们根本训练不出什么好的结果,所以只能去找个新的方法来对这种数据集进行训练,从而提出了siamese网络。
主要思想通过一个函数将输入映射到目标空间,在目标空间使用简单的距离(欧式距离等)进行对比相似度。在训练阶段去最小化来自相同类别的一对样本的损失函数值,最大化来自不同类别的一堆样本的损失函数值。
给定一组映射函数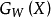 ,其中参数为W,其目的就是找一组参数W,使得当
,其中参数为W,其目的就是找一组参数W,使得当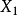 和
和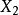 属于同一个类别时,相似性度量
属于同一个类别时,相似性度量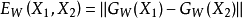 是一个较小的值;当 和 属于不同类别时,相似性度量 是一个较大的值1。
是一个较小的值;当 和 属于不同类别时,相似性度量 是一个较大的值1。
这个系统是用训练集中的成对样本进行训练,当 和 属于同一个类别时,最小化损失函数;当 和 属于不同类别时,最大化损失函数。其中 除了需要可微外不需要任何的前提假设,因为针对成对样本输入,这里两个相同的函数G,拥有一份相同的参数W,即这个结构是对称的,我们将它叫做siamese architecture。
网络结构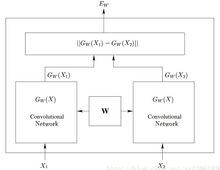
左右两边两个网络是完全相同的网络结构,它们共享相同的权值W,输入数据为一对图片(X1,X2,Y),其中Y=0表示X1和X2属于同一个人的脸,Y=1则表示不为同一个人。即相同对为(X1,X2,0),欺骗对为(X1,X2’,1)针对两个不同的输入X1和X2,分别输出低维空间结果为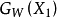 和
和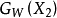 ,它们是由X1和X2经过网络映射得到的。然后将得到的这两个输出结果使用能量函数
,它们是由X1和X2经过网络映射得到的。然后将得到的这两个输出结果使用能量函数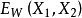 进行比较2。
进行比较2。
损失函数定义假设损失函数只和输入和参数有关,那么损失函数的形式为2:

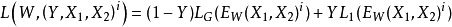
其中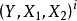 是第i个样本,是由一对图片和一个标签组成的,其中LG是只计算相同类别对图片的损失函数,LI是只计算不相同类别对图片的损失函数。P是训练的样本数。通过这样分开设计,可以达到当最小化损失函数的时候,可减少相同类别对的能量,增加不相同对的能量。很简单直观的方法是,将LG设计成单调增加,让LI单调递减,但是要保证一个前提,不相同的图片对距离肯定要比相同图片对的距离大,那么就是要满足:
是第i个样本,是由一对图片和一个标签组成的,其中LG是只计算相同类别对图片的损失函数,LI是只计算不相同类别对图片的损失函数。P是训练的样本数。通过这样分开设计,可以达到当最小化损失函数的时候,可减少相同类别对的能量,增加不相同对的能量。很简单直观的方法是,将LG设计成单调增加,让LI单调递减,但是要保证一个前提,不相同的图片对距离肯定要比相同图片对的距离大,那么就是要满足:
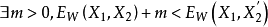
总的损失函数为:
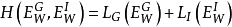 而对于单个样本的损失函数为:
而对于单个样本的损失函数为:
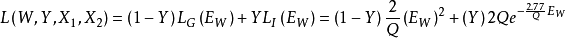
其中: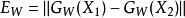 ,Q是一个常量。
,Q是一个常量。
本词条内容贡献者为:
王沛 - 副教授、副研究员 - 中国科学院工程热物理研究所


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号