

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
语音文档检索的任务就是根据用户输入的查询项,在海量语音资源中快速搜索并返回与之相关联的语音文档或语音片段。语音文档检索一般分为索引建立和查询项检索两个阶段。
发展历程语音文档检索研究起始于20世纪90年代,早期的研究大多采用大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition, LVCSR)系统与文本检索系统简单结合的方法:首先采用LVCSR系统识别语音文档得到基于词的单候选识别结果(1-Best),然后直接利用文本检索技术对其进行索引和检索。在2000年文本检索会议(Text Retrieval Conference, TREC)的SDR专题评测中,许多研究机构采用了这种检索方法对CNN、BBC、VOA等广播新闻语料进行检索实验,取得了优秀的评测结果。然而这种方法仅适用于识别率较高的广播新闻语音,对于发音不够清晰、语法不够规范的自然语音(Spontaneous Speech)来说,单候选识别结果的错误率较高,它往往仅保留语音识别过程中的最优路径,剪枝掉其余次优的路径,然而这些次优的路径也极有可能是正确的,从而造成了检索性能的下降。
为了保留更多的正确信息,近年来学者们开始研究基于多候选识别结果的语音文档检索技术。词格(Lattice)是广泛采用的一种多候选识别结果,它不仅能够补偿识别错误带来的影响,而且能够提供用于置信度计算的声学模型得分和语言模型得分。因此,基于Lattice的语音文档检索迅速发展成为了当前语音文档检索的主流技术,受到了越来越多的重视和青睐,并且相继有一些针对不同需求开发的实用系统问世,例如:美国电话电报公司(AT&T)以语音邮件浏览和搜索为主的SCAN Mail系统、惠普(HP)实验室针对网络多媒体检索开发Speechbot系统、卡内基梅隆大学(CMU)的结合语音检索、摘要以及可视化等多项技术的Informedia计划、麻省理工学院(MIT)的Lecture Browser在线课程浏览系统以及密歇根大学的Speech Find音频文件搜索引擎等。随着基于Lattice的语音文档检索技术的不断发展,美国国家标准技术局(National Institute of Standards and Technology, NIST)在2006年组织了新一轮针对大规模数据的语音查询词检索(Spoken Term Detection, STD)评测,该评测提供的测试语料中第一次正式引入了自然对话语音(电话录音、会议录音)。
在汉语语音文档检索研究方面,台湾大学语音实验室、台湾师范大学资讯工程系、香港中文大学人机通讯实验室等学术机构针对汉语的结构特点率先开展了相应的研究。国内大陆的研究工作起步相对较晚,但发展势头迅猛。在国家自然科学基金的大力支持下,清华大学、中国科技大学、哈尔滨工业大学、浙江大学、中国科学院自动化所和声学所等机构对都汉语语音文档检索技术进行了深入的研究,并取得了卓越的研究成果。例如:王新明等人开发的国语广播新闻搜索引擎“So Video”,Ye Ruizhi 等人搭建的基于 P2P(peer to peer)架构的语音检索平台“ASEKS”。另外,鉴于中国未来庞大的市场,国外机构日益重视汉语语音文档检索的研究,Microsoft、Google 等国际大公司相继在中国设立了研发中心并不断增加汉语语音文档检索系统研究的投资,同时 NIST 也把汉语普通话加入到测试语料集进行公开的语音检索评测,有力推动了该技术的发展1。
基于 Lattice 的语音文档检索基本框架基于 Lattice 的语音文档检索系统可以分成自动语音识别和查询项检索两个阶段来实现,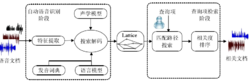 具体过程如图1所示。在自动语音识别阶段,首先对语音文档提取声学特征,然后利用声学模型、语言模型以及发音词典进行搜索解码,最终输出解码得到的多候选识别结果—Lattice。在查询项检索阶段,首先根据用户提出的查询项,在 Lattice 中搜索与查询项匹配的局部路径,并依据 Lattice 中存储的各种信息来计算匹配路径的置信度,然后利用搜索结果和其置信度计算语音文档的相关度,并根据相关度的大小对检索出的语音文档进行排序。由上述过程可以看出,Lattice 作为语音文档索引,有效地连接了自动语音识别和查询项检索两个阶段。
具体过程如图1所示。在自动语音识别阶段,首先对语音文档提取声学特征,然后利用声学模型、语言模型以及发音词典进行搜索解码,最终输出解码得到的多候选识别结果—Lattice。在查询项检索阶段,首先根据用户提出的查询项,在 Lattice 中搜索与查询项匹配的局部路径,并依据 Lattice 中存储的各种信息来计算匹配路径的置信度,然后利用搜索结果和其置信度计算语音文档的相关度,并根据相关度的大小对检索出的语音文档进行排序。由上述过程可以看出,Lattice 作为语音文档索引,有效地连接了自动语音识别和查询项检索两个阶段。
本词条内容贡献者为:
王沛 - 副教授、副研究员 - 中国科学院工程热物理研究所
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号