

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
双重筛选逐步回归亦称多对多双重筛选逐步回归法。多个因变量与多个自变量建立回归式时,不仅对自变量进行筛选,而且对因变量也同时进行筛选。并且依因变量和自变量的关系将因变量进行分组。具体地说设有p个因变量y1,y2,…yp,q个自变量x1,x2,…xq。若自变量的一部分仅对因变量的一部分有显著的相关关系,不妨设y1,y2,…yp1与x1,x2,…xq1有显著的相关关系则将它们建立回归式,剔除相关不显著的一些自变量和因变量。若另一部分yp1+1,yp1+2,…yp2与xq1+1,xq1+2,…xq2有显著的相关关系,则再将它们建立回归式,剔除相关不显著的一些自变量和因变量。如此继续下去,直到所有因变量都建立回归式为止。这样建立多组的回归式,组和组之间因变量不会有相同的,而自变量可能有共同的。这种方法称为多个因变量和多个自变量的双重筛选逐步回归法1。
双重筛选逐步回归的概念多重多元线性回归分析的计算工作量很大,而且较为繁琐,所以人们往往是将多个自变量对每一个因变量逐个进行回归建立回归模型,但这种做法会丢失多个因变量之间相关的信息,而双重筛选逐步回归分析,可以解决上述这类问题。
多个自变量与多个因变量建立回归方程时,不仅要对自变量进行筛选,而且对因变量也要进行筛选,所谓筛选即保留与之密切关系的变量,剔除与之无关紧要的变量,并且根据因变量和自变量的关系将因变量进行分组。例如研究自变量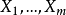 对因变量
对因变量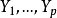 的回归方程时,如自变量的一部分仅对因变量的一部分有较密切的关系,不妨设
的回归方程时,如自变量的一部分仅对因变量的一部分有较密切的关系,不妨设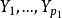 与
与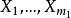 有较密切的关系,而另一部分因变量
有较密切的关系,而另一部分因变量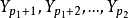 与
与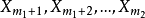 有密切关系,…,如此等等,因此,就希望将它们分组建立回归方程,此时 与 一定不会有共同的变量,而对于 与 可能有共同的变量,因为一个自变量可能对许多因变量甚至是全部因变量都有影响,这种方法就是多重筛选逐步回归法2。
有密切关系,…,如此等等,因此,就希望将它们分组建立回归方程,此时 与 一定不会有共同的变量,而对于 与 可能有共同的变量,因为一个自变量可能对许多因变量甚至是全部因变量都有影响,这种方法就是多重筛选逐步回归法2。
双重筛选逐步回归的基本思想多重筛选逐步回归的基本思想是:首先选一个因变量,不妨记为Y1,对它来筛选所有的自变量,在自变量筛选结束后,再考虑在未入选的因变量中选第二个因变量,不妨记为Y2,这时已有两个因变量Y1,Y2入选,因此要考虑Y1,Y2是否有剔除的,如果没有剔除的,则转入对Y1,Y2来筛选自变量,直到自变量筛选过程结束,再转入进行因变量的筛选,重复上述步骤,直到因变量和自变量既没有剔除也没有引入时为止,这时就建立第一组回归方程。其次从原始数据中删除第一组回归方程中已人选的因变量的资料,比如p1个,自变量的数据均不删除,重复整个过程直到因变量都有了回归方程才停止。
在上述计算过程中,由于对自变量和因变量都要进行筛选,因此需给出四个检验统计量。而且每次对变量(包括自变量、因变量)进行筛选都要对相应的相关系数阵作消去变换,因此,一开始将m+p个变量的相关系数阵R写成三个矩阵:一个记为S1,当自变量进行筛选时,对它进行消去变换;一个记为S,当因变量筛选时,对它进行消去变换;一个记为S2,不管是对自变量还是因变量进行筛选对它都要做消去变换2。
双重筛选逐步回归的步骤设自变量为 ,因变量为 ,为计算方便,将 记为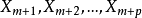 ,取n次观测数据,于是原始数据矩阵为
,取n次观测数据,于是原始数据矩阵为
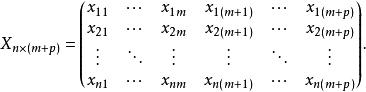 第一步:计算m个自变量和p个因变量的相关系数矩阵
第一步:计算m个自变量和p个因变量的相关系数矩阵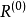
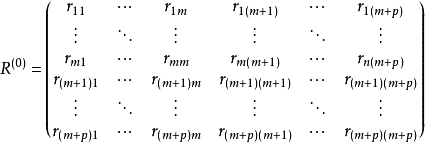
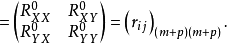
第二步:建立第一组回归方程
1.由于要建立第一组回归方程,所以,令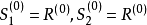 ,把
,把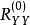 记为
记为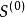 。
。
2.给定引入变量的临界值F进和剔除变量的临界值F出,取临界值F进≥F出≥0以保证逐步筛选变量过程在有限步后停止。
3.选取第一个因变量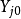 。
。
4.逐个检查是否需要剔除自变量。
5.逐个检查是否需要引入自变量。
6.逐个检查是否需要剔除因变量。
7.考虑引入因变量。
8.建立第一组回归方程。
第三步:在原始资料阵中全部删去已入选第一组回归方程中的因变量的资料,而自变量的资料均不删去,再重复整个过程,可求出第二组回归方程。如此往复,直到全部因变量都有回归方程为止2。
本词条内容贡献者为:
刘军 - 副研究员 - 中国科学院工程热物理研究所
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号