

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
复判定系数及R2=1-SSE/SST(其中SSE为残差平方和,SST为总平方和)是用来说明因变量的变动中可以用自变量来解释的比例。它可以反映模型的好坏,但由于随着自变量的增加,SSE只会减少,不会变大,而对给定的一组变量观察值来说SST却总是恒定不变,故变量引进模型只会导致R2增大而不会缩小,这极易使人产生错觉,似乎自变量越多越奸。其结果是过多引进一些效率不高的自变量。而统计量1-((n-1)/(n-p-1).(SSE/SST))称为调整的复判定系数,当自变量增加,SSE减小时,其自由度n-p-1就变小,这样调整的复判定系数就不会象R2那样自变量越多越大,从而可能避免引进过多的不必要的自变量,使自变量的选择更合理1。
基本介绍复判定系数是指在多元线性回归分析中,回归离差平方和占总离差平方和的比重,一般也称为多重判定系数(multiple coefficient of determination),或简称为判定系数。
与一元线性回归的情形一样,多元线性回归的复判定系数的计算公式是:

R2表示因变量Y的全部变差中可由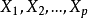 的差异解释的部分所占的比例。
的差异解释的部分所占的比例。
回归方程的精度与简洁性的标准往往不可能同时得到最大化的满足。在回归方程精度的测量指标中,最常用的指标是复判定系数。复判定系数的一个重要性质是,它是出现在模型中的自变量个数的非减函数,即随着自变量个数的增大,R2几乎必然增大,至少是不减小。为了看清楚这一点,我们先看R2的计算公式:
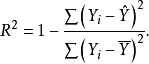
公式中 与模型中X变量的个数没有关系,但
与模型中X变量的个数没有关系,但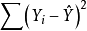 与自变量的个数有关,直观上,随着X变量个数的增加,其很可能减小(至少不会增大),随之R2会相应增大。这一变化也可通过图1所示的图形表现出来2。
与自变量的个数有关,直观上,随着X变量个数的增加,其很可能减小(至少不会增大),随之R2会相应增大。这一变化也可通过图1所示的图形表现出来2。

调整后的判定系数建立回归模型时,不能一味地通过增多自变量的个数来实现回归精度的提高。因为判定系数逐步提高的过程,回归方程也就逐渐背离了其简洁的原则。因而在对回归方程进行评价时需要进行综合的考虑和评价。即在考虑模型精度的同时也要考虑模型的简洁性。进行模型的评价或模型的比较时,必须要考虑到模型中出现的自变量的个数,计算调整后的判定系数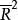 。
。

调整是指对判定系数R2计算公式中平方和所涉及的自由度的调整,在一个涉及p+1个参数的模型中,SSE有n-p-1个自由度,而SST有n-1个自由度2。
判定系数与调整后的判定系数的关系与 的关系是:
的关系是:

从式子中可以看到:
1)p>1时,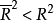 ,这意味着增加X变量的个数,调整后的比未调整的
,这意味着增加X变量的个数,调整后的比未调整的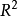 增加的慢些。
增加的慢些。
2)虽然R2必定是非负的,但可以是负的。
调整后的判定系数与自变量个数之间的关系如图2所示。
根据判定系数,不管是通过调整后的还是未经调整的判定系数来比较两个模型,一定要注意样本大小n和因变量都必须相同,而自变量可以采取不同的形式与内容。例如:
 这两个回归方程的R2项是不可比较的。
这两个回归方程的R2项是不可比较的。
因为按定义,R2度量的是因变量的变异可以由自变量解释的部分,所 中R2度量的是X1和X2解释
中R2度量的是X1和X2解释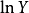 的变异部分;而
的变异部分;而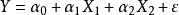 中的
中的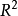 度量的是X1和X2解释Y的变异部分,两者不是同一回事,两个判定系数所度量的不是同一问题。
度量的是X1和X2解释Y的变异部分,两者不是同一回事,两个判定系数所度量的不是同一问题。
进行多元线性回归模型的比较与评价最常用的测量指标是调整后的判定系数,此外,还有其他的准则,包括赤池的信息准则(Akaike Information Criterion,AIC)和施瓦茨准则(Schwarz Criterion,SC)等2。
本词条内容贡献者为:
刘军 - 副研究员 - 中国科学院工程热物理研究所
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号