

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
在数学,尤其是概率论和相关领域中,归一化指数函数,或称Softmax函数,是逻辑函数的一种推广。它能将一个含任意实数的K维向量z“压缩”到另一个K维实向量σ(z)中,使得每一个元素的范围都在(0,1)之间,并且所有元素的和为1。该函数多于多分类问题中。
简介归一化指数函数,或Softmax函数,实际上是有限项离散概率分布的梯度对数归一化。因此,Softmax函数在包括 多项逻辑回归,多项线性判别分析,朴素贝叶斯分类器和人工神经网络等的多种基于概率的多分类问题方法中都有着广泛应用。特别地,在多项逻辑回归和线性判别分析中,函数的输入是从K个不同的线性函数得到的结果,而样本向量 x 属于第 j 个分类的概率为:
 这可以被视作K个线性函数的Softmax函数的复合。Softmax 回归模型是解决多类回归问题的算法,是当前深度学习研究中广泛使用在深度网络有监督学习部分的分类器1,经常与交叉熵损失函数联合使用。
这可以被视作K个线性函数的Softmax函数的复合。Softmax 回归模型是解决多类回归问题的算法,是当前深度学习研究中广泛使用在深度网络有监督学习部分的分类器1,经常与交叉熵损失函数联合使用。
以下是归一化指数函数代码实现示例,输入向量 [1,2,3,4,1,2,3]对应的Softmax函数的值为[0.024,0.064,0.175,0.475,0.024,0.064,0.175]。输出向量中拥有最大权重的项对应着输入向量中的最大值“4”。这也显示了这个函数通常的意义:对向量进行归一化,凸显其中最大的值并抑制远低于最大值的其他分量。下面是使用Python进行函数计算的示例代码:
import mathz = [1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0]z_exp = [math.exp(i) for i in z] print(z_exp) # Result: [2.72, 7.39, 20.09, 54.6, 2.72, 7.39, 20.09] sum_z_exp = sum(z_exp) print(sum_z_exp) # Result: 114.98 # Result: [0.024, 0.064, 0.175, 0.475, 0.024, 0.064, 0.175]softmax = [round(i / sum_z_exp, 3) for i in z_exp]print(softmax) 逻辑函数逻辑函数或逻辑曲线是一种常见的S函数,它是皮埃尔·弗朗索瓦·韦吕勒在1844或1845年在研究它与人口增长的关系时命名的。广义Logistic曲线可以模仿一些情况人口增长(P)的S形曲线。起初阶段大致是指数增长;然后随着开始变得饱和,增加变慢;最后,达到成熟时增加停止。
分类器分类是数据挖掘的一种非常重要的方法。分类的概念是在已有数据的基础上学会一个分类函数或构造出一个分类模型(即我们通常所说的分类器(Classifier))。该函数或模型能够把数据库中的数据纪录映射到给定类别中的某一个,从而可以应用于数据预测。总之,分类器是数据挖掘中对样本进行分类的方法的统称,包含决策树、逻辑回归、朴素贝叶斯、神经网络等算法。分类器的构造和实施大体会经过以下几个步骤:
选定样本(包含正样本和负样本),将所有样本分成训练样本和测试样本两部分。
在训练样本上执行分类器算法,生成分类模型。
在测试样本上执行分类模型,生成预测结果。
根据预测结果,计算必要的评估指标,评估分类模型的性能。
交叉熵交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从压缩的角度来看,每个词平均要用几个位来编码。复杂度的意义是用该模型表示这一文本平均的分支数,其倒数可视为每个词的平均概率。平滑是指对没观察到的N元组合赋予一个概率值,以保证词序列总能通过语言模型得到一个概率值。通常使用的平滑技术有图灵估计、删除插值平滑、Katz平滑和Kneser-Ney平滑。交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
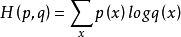
本词条内容贡献者为:
宋春霖 - 副教授 - 江南大学
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号