科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2021-05-28
少样本学习
论文标题:
True Few-Shot Learning with Language Models
论文链接:
https://arxiv.org/abs/2105.11447
代码链接:
https://github.com/ethanjperez/true_few_shot
预训练语言模型 (LM) 在许多任务中表现良好,即使是从少数样本中学习,但之前的工作用许多保留样本微调学习的各方面,如超参数、训练目标和自然语言模板(“提示“)。本文评估了保留样本不可用时,语言模型的少样本能力,并把这种设置称为真少样本学习。测试了两种模型选择标准,交叉验证和最小描述长度,用于在真少样本学习环境中选择语言模型的提示和超参数。
平均来说,这两种方法都略优于随机选择,大大低于基于保留样本的选择。此外,选择标准往往倾向于选择那些表现明显比随机选择更差的模型。即使考虑到在选择过程中对模型真实性能的不确定性,以及改变用于选择的计算量和样本数量,也发现了类似的结果。研究结果表明,考虑到少样本模型选择的难度,之前的工作大大高估了语言模型的真少样本能力。
来源: PaperWeekly
原文链接:http://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247527832&idx=2&sn=68b0d56b411de98f93958e92d20ba1a3
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn

东北大学研究团队发布TechGPT2.0大语言模型
神经语言模型
语言模型可预测突变识别疫苗有效目标

全新instruction调优,零样本性能超越小样本,谷歌1370亿参数新模型比GPT-3更强

父亲在儿童语言发展中扮演重要角色
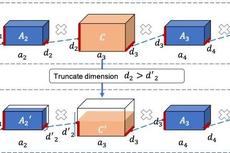
当模型压缩遇上量子力学——基于矩阵乘积算符的预训练语言模型轻量化微调

大语言模型对著名数学问题有“新见解”

基于预训练语言模型的文本生成研究综述

Meta发布开源大语言模型,号称优于ChatGPT

谷歌提出多语言BERT模型:可为109种语言生成与语言无关的跨语言句子嵌入


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号