科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2019-07-25
来源:中国科学院自动化研究所
CASIA解锁更多智能之美【INTERSPEECH2019】自动化所在语音内容识别方向获新进展
【编者按】2019年9月15至19日,全球语音顶级学术会议INTERSPEECH2019将在在奥地利格拉茨举行。INTERSPEECH是由国际语音通信协会ISCA(International Speech Communication Association)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会,该会议每年举办一次,吸引了全球语音信号领域以及人工智能领域知名学者、企业以及研发人员参加。
自动化研究所智能交互团队共有9篇论文入选该会议,小编接下来将分别从语音内容识别以及语音情感识别两大方面进行介绍。本次介绍《基于知识迁移的端到端语音识别系统》、《基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测》、《基于自注意力机制的端到端语音转写模型》、《基于区分性学习和深度嵌入式特征的语音分离方法》等4项研究。
01基于知识迁移的端到端语音识别系统
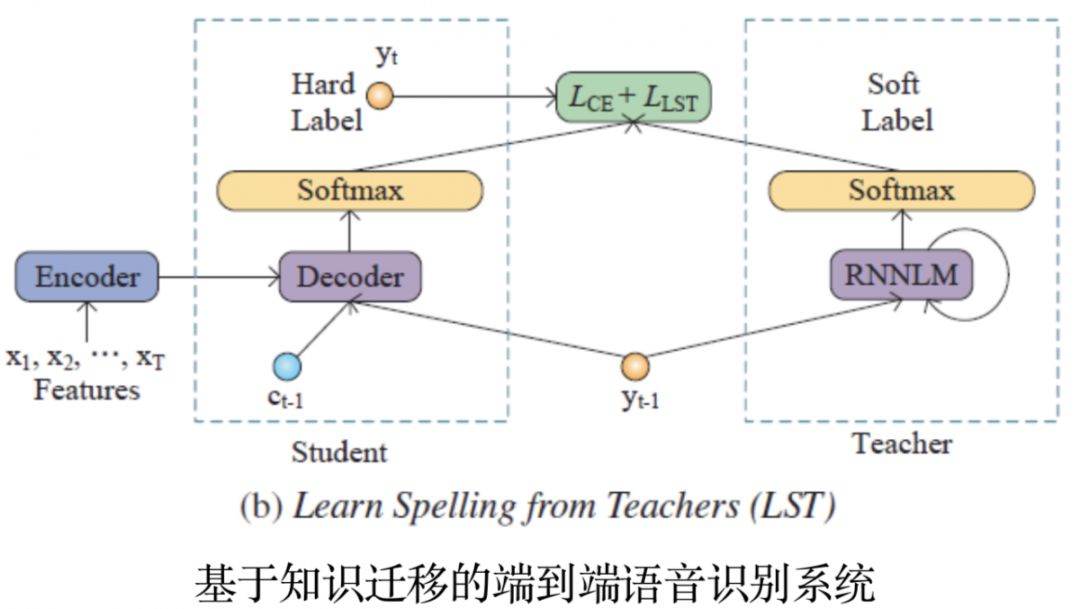
现有端到端语音识别系统难以有效利用外部文本语料中的语言学知识,针对这一问题,陶建华、易江燕、白烨等人提出采用知识迁移的方法,首先对大规模外部文本训练语言模型,然后将该语言模型中的知识迁移到端到端语音识别系统中。这种方法利用了外部语言模型提供词的先验分布软标签,并采用KL散度进行优化,使语音识别系统输出的分布与外部语言模型输出的分布接近,从而有效提高语音识别的准确率。
Learn Spelling from Teachers: Integrating Language Models into Sequence-to-Sequence Models
Ye Bai, Jiangyan Yi, Jianhua Tao, Zhengkun Tian, Zhengqi Wen
02基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测
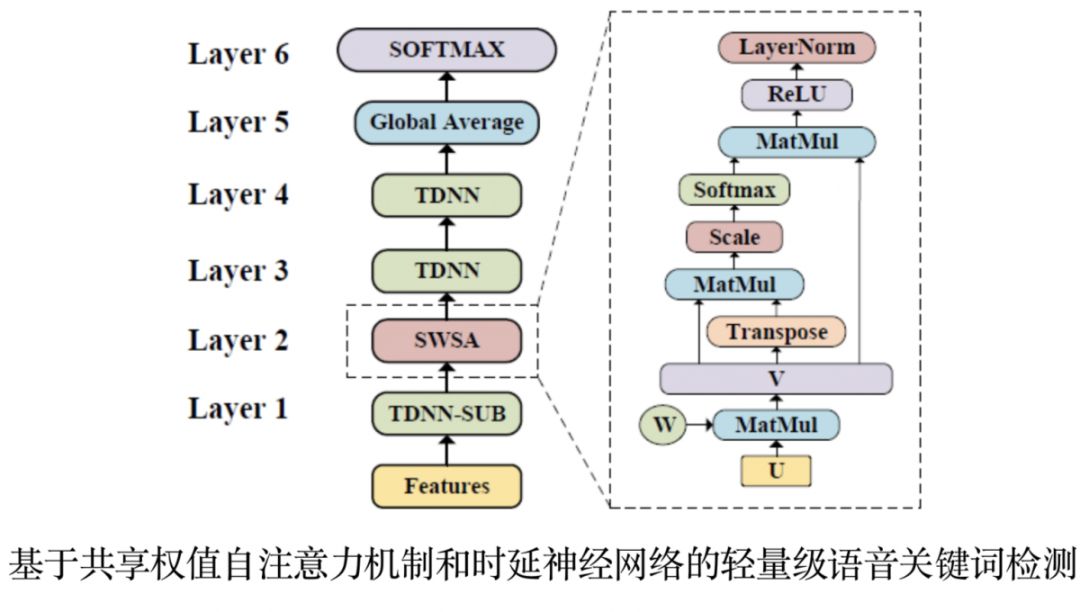
语音关键词检测在智能家居、智能车载等场景中有着重要作用。面向终端设备的语音关键词检测对算法的时间复杂度和空间复杂度有着很高的要求。当前主流的基于残差神经网络的语音关键词检测,需要20万以上的参数,难以在终端设备上应用。
为了解决这一问题,陶建华、易江燕、白烨等人提出基于共享权值自注意力机制和时延神经网络的轻量级语音关键词检测方法。该方法采用时延神经网络进行降采样,通过自注意力机制捕获时序相关性;并采用共享权值的方法,将自注意力机制中的多个矩阵共享,使其映射到相同的特征空间,从而进一步压缩了模型的尺寸。与目前的性能最好的基于残差神经网络的语音关键词检测模型相比,我们提出方法在识别准确率接近的前提下,模型大小仅为残差网络模型的1/20,有效降低了算法复杂度。
A Time Delay Neural Network with Shared Weight Self-Attention for Small-Footprint Keyword Spotting
Ye Bai, Jiangyan Yi, Jianhua Tao, Zhengqi Wen, Zhengkun Tian, Chenghao Zhao, Cunhang Fan
03基于自注意力机制的端到端语音转写模型

针对RNN-Transducer模型存在收敛速度慢、难以有效进行并行训练的问题,陶建华、易江燕、田正坤等人提出了一种Self-attention Transducer (SA-T)模型,主要在以下三个方面实现了改进:(1)通过自注意力机制替代RNN进行建模,有效提高了模型训练的速度;(2)为了使SA-T能够进行流式的语音识别和解码,进一步引入了Chunk-Flow机制,通过限制自注意力机制范围对局部依赖信息进行建模,并通过堆叠多层网络对长距离依赖信息进行建模;(3)受CTC-CE联合优化启发,将交叉熵正则化引入到SA-T模型中,提出Path-Aware Regularization(PAR),通过先验知识引入一条可行的对齐路径,在训练过程中重点优化该路径。
经验证,上述改进有效提高了模型训练速度及识别效果。
Self-Attention Transducers for End-to-End Speech Recognition
Zhengkun Tian, Jiangyan Yi, Jianhua Tao, Ye Bai and Zhengqi Wen
04基于区分性学习和深度嵌入式特征的语音分离方法
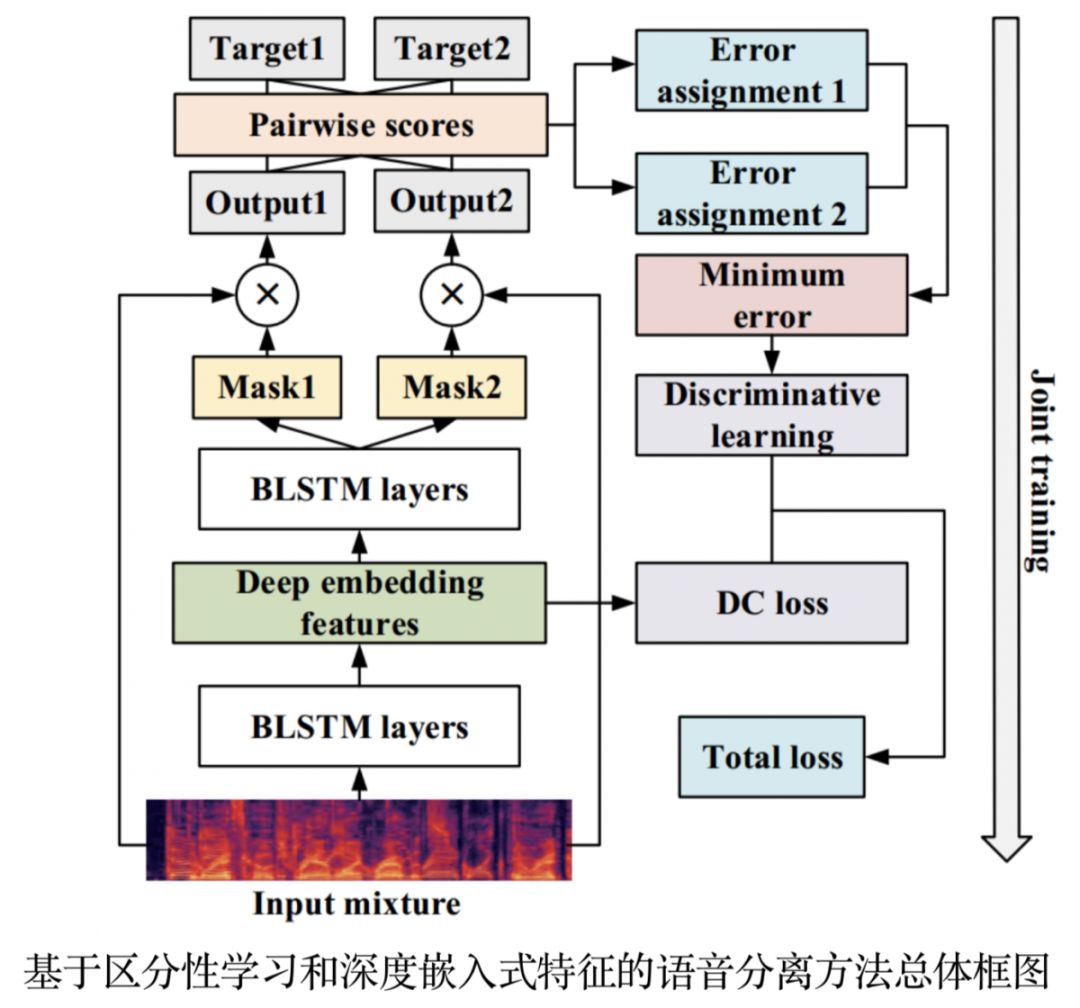
语音分离又称为鸡尾酒会问题,其目标是从同时含有多个说话人的混合语音信号中分离出不同说话人的信号。当一段语音中同时含有多个说话人时,会严重影响语音识别和说话人识别的性能。
目前解决这一问题的两种主流方法分别是:深度聚类(DC, deep clustering)算法和排列不变性训练(PIT, permutation invariant training)准则算法。深度聚类算法在训练过程中不能以真实的干净语音作为目标,性能受限于k-means聚类算法;而PIT算法其输入特征区分性不足。
针对DC和PIT算法的局限性,陶建华、刘斌、范存航等人提出了基于区分性学习和深度嵌入式特征的语音分离方法。首先,利用DC提取一个具有区分性的深度嵌入式特征,然后将该特征输入到PIT算法中进行语音分离。同时,为了增大不同说话人之间的距离,减小相同说话人之间的距离,引入了区分性学习目标准则,进一步提升算法的性能。所提方法在WSJ0-2mix语音分离公开数据库上获得较大的性能提升。
Discrimination Learning for Monaural Speech Separation Using Deep Embedding Features
Cunhang Fan, Bin Liu, Jianhua Tao, Jiangyan Yi, Zhengqi Wen
来源:casia1956 中国科学院自动化研究所
原文链接:http://mp.weixin.qq.com/s?__biz=MzA5MDU0MTYxNw==&mid=2650782766&idx=1&sn=9d1cf6acef6033367177b3944d09dfec&chksm=88010770bf768e66d8406094c9027cfb1be565ce1912501a584234aff7a877e0eb5d40cfbfef&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
神经网络传输协议
74KB图片也高清,谷歌用神经网络打造图像压缩新算法

如何入手卷积神经网络

忘掉算法,人工智能的未来还要看硬件突破
单隐藏层神经网络

我国成功研发智能辅助驾驶系统
IBM研发出无监督式机器学习算法

当神经网络遇上量子计算
提升神经网络

借助神经网络,科学家们用手机拍出了“单反质量”照片


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号