科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-10-30
来源:中国人工智能学会
转自 AI科技大本营

作者 | 斯图尔特·罗素
来源 | 《AI新生》
出品 | AI科技大本营
经济学家通过为人类受试者提供选择来套取他们的偏好。该技术广泛应用于产品设计、营销和交互式电子商务系统中。例如,汽车设计师向受测试者提供具有不同油漆颜色、座位安排、后备厢大小、电池容量、杯架等选项的汽车,以此来了解人们关心哪些汽车功能,以及他们愿意为这些功能支付多少钱。另一个重要应用是在医学领域,肿瘤学家在考虑截肢的可能性时,可能需要评估病人在行动能力和预期寿命之间的偏好。当然,披萨餐厅想知道人们愿意为香肠披萨支付的价格比普通披萨高多少。

如何寻找奖励信号优化复杂行为?
套取偏好通常只考虑在多个对象之间做出的单一选择,我们假设这些对象的价值对受试者而言是显而易见的。我们目前还不清楚如何将其拓展到对未来生活的偏好上。为此,我们(和机器)需要从长期的行为观察中学习,这涉及具有多种选择和不确定结果的行为。
1997年初,我和同事迈克尔·迪金森、鲍勃·弗尔讨论了我们如何应用机器学习的思想来理解动物的运动行为。迈克尔仔细研究了果蝇翅膀的运动。而鲍勃特别喜欢令人毛骨悚然的爬虫,他为蟑螂制作了一台小型跑步机,以便观察它们的步态如何随着速度的变化而变化。我们认为,利用强化学习来训练机器人或模拟昆虫,以此重现这些复杂的行为是可能的。我们面临的问题是,我们不知道使用什么奖励信号,不知道苍蝇和蟑螂在优化什么。没有这些信息,我们就无法应用强化学习来训练虚拟昆虫,所以我们陷入了困境。
一天,我从我们在伯克利的房子去当地超市。这条路有一个下坡,我注意到,这个斜坡使我走路的方式发生了轻微的变化,我相信大多数人都会这样。此外,几十年中发生的数次小地震造成了路面不平坦,所以走在上面的人会发生额外的步态变化,由于地面高度无法预测,我的脚抬得更高了一点,下落时也不那么生硬。当我思考这些平凡的生活观察时,我意识到我们弄错了。当强化学习从奖励中产生行为时,我们实际上想要的恰恰相反:学习给定行为的奖励。我们已经有了由苍蝇和蟑螂产生的行为,我们想知道这种行为所优化的具体奖励信号。换言之,我们需要逆强化学习算法(IRL)。(当时我还不知道,还有一个类似的问题曾被研究过,它被称为“马尔科夫决策过程的结构式估计方法”,这是诺贝尔奖得主汤姆·萨金特(Tom Sargent)在20世纪70年代末开创的一个领域。)这样的算法不仅可以解释动物的行为,还可以预测它们在新环境下的行为。
或许,理解逆强化学习算法的最简单方法是:观察者从对真实的奖励函数的一些模糊估计开始,然后随着观察到更多的行为而细化这个估计,使之更精确。或者,用贝叶斯的理论来解释:从可能的奖励函数的先验概率开始,然后随着证据的增加来更新奖励函数的概率分布。

如何让机器将人类行为转化为人类偏好?
逆强化学习如今已经是构建有效的人工智能系统的重要工具,但它做了一些简化的假设。
第一,机器人一旦通过观察人类学会了奖励函数,它就会采用奖励函数,这样它就可以执行相同的任务。这对驾驶汽车或驾驶直升机来说没问题,但对于喝咖啡不行:一个观察我早晨习惯的机器人应该知道我(有时)想喝咖啡,但不应该知道它自己想喝咖啡。解决这个问题很容易,我们只需确保机器人将偏好与人类联系起来,而不是与自身联系起来。
逆强化学习中的第二个简化假设是,机器人正在观察一个人类解决单智能体决策问题。例如,假设机器人在医学院,通过观察人类专家来学习成为外科医生。逆强化学习算法假设人类通常以最佳方式进行手术,就好像机器人不在那里一样。但事实并非如此:人类外科医生的动机是让机器人(像其他医科学生一样)学得又快又好,这样她就会大大改变自己的行为。她可以边走边解释她在做什么;她可以指出需要避免的错误,比如切口太深或伤口缝合太紧;她可以描述万一手术中出现问题,应当采取什么应急方案。在单独进行手术时,这些行为都没有意义,因此逆强化学习算法将无法解释这些行为所暗示的偏好。出于这个原因,我们需要将逆强化学习从单智能体设置发展到多智能体设置,也就是说,我们需要设计一种学习算法,当人和机器人是同一环境的一部分并且相互交互时,该算法必须发挥作用。
当一个人和一个机器人处于同一环境中的时候,我们就进入了博弈论的领域。在这个理论的第一个版本中,我们假设人类有偏好,并根据这些偏好行事。机器人不知道人类有什么偏好,但它无论如何都想满足他们。我们称这种情况为“辅助博弈”,因为根据定义,机器人应该对人类有所帮助。
辅助博弈实例化了我在《AI新生》中提到的三个原则:机器人的唯一目标是满足人类的偏好,它最初并不知道人类的偏好是什么,以及它可以通过观察人类的行为来学习更多。也许辅助博弈最有趣的特性是,通过解决博弈问题,机器人可以自己弄明白如何将人类行为转化为有关人类偏好的信息。

机器人罗比会梦见回形针吗?
辅助博弈的一个例子是回形针博弈。这是一个非常简单的游戏,在这个游戏中,人类哈里特有一种动机来向机器人罗比“发送”一些她的偏好信息。罗比能够解读这个信号,因为它能玩这个游戏, 由此它能理解哈里特有什么样的偏好,以便让她发出那样的信号。
游戏的步骤如图12所示,涉及制作回形针和订书钉。哈里特的偏好是通过一个收益函数来表达的,该函数取决于生产的回形针和订书钉的数量,两者之间有一定的“汇率”。例如,她可能会把回形针的价值定为45美分,将订书钉的价值定为55美分。(我们将假设这两个价值的总和始终为1.00美元,重要的只有比率。)因此,如果生产10个回形针和20个订书钉,哈里特的收益将是10×45美分+20×55美分=15.50美元。机器人罗比一开始完全不确定哈里特的偏好:他对回形针的价值有一个均匀分布(也就是说,价值有可能是从0美分到1.00美元的任何值)。哈里特先做了选择,她可以选择制作2个回形针,或2个订书钉,或每种各1 个。然后,罗比选择制作90个回形针,或90个订书钉,或每种各50个。
请注意,如果哈里特自己做这件事,做了2个订书钉,价值为1.10美元。但是罗比在看着,它从她的选择中学习。它到底学到了什么?这取决于哈里特如何做出选择。哈里特是如何做出选择的?这取决于罗比如何解释它。所以,我们似乎遇到了一个循环问题!这在博弈论问题中很典型,也是纳什提出纳什平衡的原因。
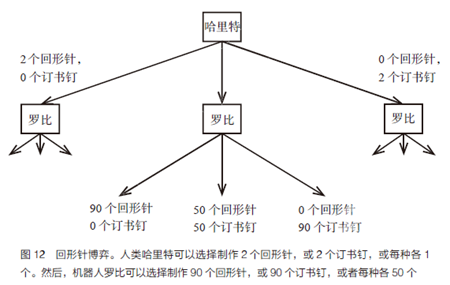
为了找到一个均衡的解决方案,我们需要为哈里特和罗比确定策略,假设任意一方的策略保持不变,则双方都没有改变自己策略的动机。哈里特的一个策略是,根据她的偏好,指定要做多少回形针和订书钉;罗比的一个策略是,根据哈里特的行动,指定要做多少回形针和订书钉。
事实证明,似乎只有一个均衡解。
• 哈里特根据她对回形针的估价做出如下决定:
如果价值低于44.6美分,我就制作0个回形针和2个订书钉;
如果价值在44.6-55.4美分之间,我就每种各制作1个;
如果价值大于55.4美分,我就制作2个回形针和0个订书钉。
• 罗比回应如下:
如果哈里特制作0个回形针和2个订书钉,我就制作90个订书钉;
如果哈里特每种各制作1个,我就每种各制作50个;
如果哈里特制作2个回形针和0个订书钉,我就只制作90个回形针。
通过这种策略,哈里特实际上是在用一种简单的代码(如果你喜欢,也可以说是一种语言)告诉罗比她的偏好,这种简单的代码是从均衡分析中产生的。就像外科医生教学的例子一样,单智能体逆强化学习算法无法理解这段代码。还要注意,罗比从来没有确切地了解哈里特的偏好,但是它学到了足够多的东西来代表她采取最佳行动,也就是说,它的行为就像确实知道哈里特的偏好一样。在陈述的假设下和哈里特在正确玩游戏的假设下,我们可以证明罗比对哈里特是有益的。
人们也可以构建问题,罗比会像一个好学生一样问问题,而哈里特会像一个好老师一样告诉罗比要避免的陷阱。之所以会出现这些行为,并不是因为我们编写了让罗比听从哈里特的脚本,而是因为这是哈里特和罗比参与的辅助博弈的最佳解决方案。
我们还有很多方法来完善模型或将模型嵌入复杂的决策问题中。然而我相信,核心理念——有益的、顺从的行为和机器对人类偏好的不确定性之间的重要联系,会经受住这些细化和复杂化的考验。
作者介绍
斯图尔特·罗素(Stuart Russell)
加州大学伯克利分校计算机科学家,人类兼容人工智能中心(CHAI) 主任,人工智能研究实验室指导委员会(BAIR)成员。中信出版集团·前沿·《AI 新生》
世界经济论坛人工智能和机器人委员会副主席,美国科学促进会 (AAAS)会士,美国人工智能协会(AAAI)会士。
曾与谷歌研究总监彼得·诺维格合著,出版了人工智能领域里的“标 准教科书”《人工智能》,该书被 128 个国家的 1400 多所大学使用。
获得过多项科学荣誉,包括美国国家科学基金会总统青年研究员奖、 国际人工智能联合会议(IJCAI)计算机与思想奖、国际计算机学会 (ACM)卡尔斯特朗杰出教育家奖等,并受邀在 TED、世界经济论坛演 讲。
本文整理自《AI新生》 斯图尔特·罗素著 中信出版集团 2020.10
来源:CAAI-1981 中国人工智能学会
原文链接:https://mp.weixin.qq.com/s?__biz=MjM5ODIwNjEzNQ==&mid=2649815506&idx=3&sn=c24c6fd1d2e46e56b7105840286ed7af&chksm=beca160a89bd9f1ca2b6eb1d04f3c04033979ebc2b764fa8be10d17917d8f83b2ef36243e52f#rd
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn

浮在水面上的曲别针

【WRC 大咖观点】张钹《人工智能与机器人》
人工智能+机器人:制造业效率提升新机会

聚焦2019世界机器人大会 人工智能重塑机器人产业

NATURE 人工智能 | 神奇的粒子机器人

自动复原的曲别针
“制造业转型升级”论坛在深圳举行
顺德区数控机械创新应用示范工程及自动化技术交流会召开

NATURE 人工智能 | 神奇的粒子机器人

聚焦2019世界机器人大会 人工智能重塑机器人产业


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号