

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
粒子群算法,也称粒子群优化算法或鸟群觅食算法(Particle Swarm Optimization),缩写为 PSO, 是近年来由J. Kennedy和R. C. Eberhart等开发的一种新的进化算法(Evolutionary Algorithm - EA)。PSO 算法属于进化算法的一种,和模拟退火算法相似,它也是从随机解出发,通过迭代寻找最优解,它也是通过适应度来评价解的品质,但它比遗传算法规则更为简单,它没有遗传算法的“交叉”(Crossover) 和“变异”(Mutation) 操作,它通过追随当前搜索到的最优值来寻找全局最优。这种算法以其实现容易、精度高、收敛快等优点引起了学术界的重视,并且在解决实际问题中展示了其优越性。粒子群算法是一种并行算法。1
简介粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由Eberhart 博士和kennedy 博士提出,源于对鸟群捕食的行为研究 。该算法最初是受到飞鸟集群活动的规律性启发,进而利用群体智能建立的一个简化模型。粒子群算法在对动物集群活动行为观察基础上,利用群体中的个体对信息的共享使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得最优解。
起源如前所述,PSO模拟鸟群的捕食行为。设想这样一个场景:一群鸟在随机搜索食物。在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是他们知道当前的位置离食物还有多远。那么找到食物的最优策略是什么呢。最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
PSO从这种模型中得到启示并用于解决优化问题。PSO中,每个优化问题的解都是搜索空间中的一只鸟。我们称之为“粒子”。所有的粒子都有一个由被优化的函数决定的适应值(fitness value),每个粒子还有一个速度决定他们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO 初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个"极值"来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值pBest。另一个极值是整个种群目前找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分作为粒子的邻居,那么在所有邻居中的极值就是局部极值。
粒子公式:
在找到这两个最优值时,粒子根据如下的公式来更新自己的速度和新的位置:
v[] = w * v[] + c1 * rand() * (pbest[] - present[]) + c2 * rand() * (gbest[] - present[]) (a)
present[] = present[] + v[] (b)
v[] 是粒子的速度, w是惯性权重,present[] 是当前粒子的位置. pbest[] and gbest[] 如前定义. rand () 是介于(0, 1)之间的随机数. c1, c2 是学习因子. 通常 c1 = c2 = 2.
程序的伪代码如下
For each particle
____Initialize particle
END
Do
____For each particle
________Calculate fitness value
________If the fitness value is better than the best fitness value (pBest) in history
____________set current value as the new pBest
____End
____Choose the particle with the best fitness value of all the particles as the gBest
____For each particle
________Calculate particle velocity according equation (a)
________Update particle position according equation (b)
____End
While maximum iterations or minimum error criteria is not attained
在每一维粒子的速度都会被限制在一个最大速度Vmax,如果某一维更新后的速度超过用户设定的Vmax,那么这一维的速度就被限定为Vmax
应用PSO同遗传算法类似,是一种基于迭代的优化算法。系统初始化为一组随机解,通过迭代搜寻最优值。但是它没有遗传算法用的交叉(crossover)以及变异(mutation),而是粒子在解空间追随最优的粒子进行搜索。同遗传算法比较,PSO的优势在于简单容易实现并且没有许多参数需要调整。目前已广泛应用于函数优化,神经网络训练,模糊系统控制以及其他遗传算法的应用领域。
近年来,一些学者将PSO算法推广到约束优化问题,其关键在于如何处理好约束,即解的可行性。如果约束处理的不好,其优化的结果往往会出现不能够收敛和结果是空集的状况。基于PSO算法的约束优化工作主要分为两类:
(1)罚函数法。罚函数的目的是将约束优化问题转化成无约束优化问题。
(2)将粒子群的搜索范围都限制在条件约束簇内,即在可行解范围内寻优。
根据文献介绍,Parsopoulos等采用罚函数法,利用非固定多段映射函数对约束优化问题进行转化,再利用PSO算法求解转化后问题,仿真结果显示PSO算法相对遗传算法更具有优越性,但其罚函数的设计过于复杂,不利于求解;Hu等采用可行解保留政策处理约束,即一方面更新存储中所有粒子时仅保留可行解,另一方面在初始化阶段所有粒子均从可行解空间取值,然而初始可行解空间对于许多问题是很难确定的;Ray等提出了具有多层信息共享策略的粒子群原理来处理约束,根据约束矩阵采用多层Pareto排序机制来产生优良粒子,进而用一些优良的粒子来决定其余个体的搜索方向。
但是,目前有关运用PSO算法方便实用地处理多约束目标优化问题的理论成果还不多。处理多约束优化问题的方法有很多,但用PSO算法处理此类问题目前技术并不成熟,这里就不介绍了。
比较演化计算技术大多数演化计算技术都是用同样的过程:
1.种群随机初始化;
2.对种群内的每一个个体计算适应值(fitness value),适应值与最优解的距离直接有关;
3.种群根据适应值进行复制;
4.如果终止条件满足的话,就停止,否则转步骤2。
从以上步骤,我们可以看到PSO和GA有很多共同之处。两者都随机初始化种群,而且都使用适应值来评价系统,而且都根据适应值来进行一定的随机搜索。两个系统都不是保证一定找到最优解 。
记忆PSO没有遗传操作如交叉(crossover)和变异(mutation),而是根据自己的速度来决定搜索。粒子还有一个重要的特点,就是有记忆。
与遗传算法比较, PSO 的信息共享机制是很不同的。在遗传算法中,染色体(chromosomes) 互相共享信息,所以整个种群的移动是比较均匀的向最优区域移动。在PSO中, 只有gBest (or pBest) 给出信息给其他的粒子,这是单向的信息流动。整个搜索更新过程是跟随当前最优解的过程。
与遗传算法比较,在大多数的情况下,所有的粒子可能更快的收敛于最优解。
训练过程这里用一个简单的例子说明PSO训练神经网络的过程。这个例子使用分类问题的基准函数(Benchmark function)IRIS数据集。(Iris 是一种鸢尾属植物) 在数据记录中,每组数据包含Iris花的四种属性:萼片长度,萼片宽度,花瓣长度,和花瓣宽度,三种不同的花各有50组数据。这样总共有150组数据或模式。
我们用3层的神经网络来做分类。现在有四个输入和三个输出。所以神经网络的输入层有4个节点,输出层有3个节点我们也可以动态调节隐含层节点的数目,不过这里我们假定隐含层有6个节点。我们也可以训练神经网络中其他的参数。不过这里我们只是来确定网络权重。粒子就表示神经网络的一组权重,应该是4*6+6*3=42个参数。权重的范围设定为[-100,100] (这只是一个例子,在实际情况中可能需要试验调整)。在完成编码以后,我们需要确定适应函数。对于分类问题,我们把所有的数据送入神经网络,网络的权重由粒子的参数决定。然后记录所有的错误分类的数目作为那个粒子的适应值。现在我们就利用PSO来训练神经网络来获得尽可能低的错误分类数目。PSO本身并没有很多的参数需要调整。所以在实验中只需要调整隐含层的节点数目和权重的范围以取得较好的分类效果。
从上面的例子我们可以看到应用PSO解决优化问题的过程中有两个重要的步骤:问题解的编码和适应度函数。
不需要像遗传算法一样是二进制编码(或者采用针对实数的遗传操作)。例如对于问题 求解,粒子可以直接编码为
求解,粒子可以直接编码为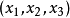 , 而适应度函数就是f(x)。接着我们就可以利用前面的过程去寻优。这个寻优过程是一个叠代过程,中止条件一般为设置为达到最大循环数或者最小错误。
, 而适应度函数就是f(x)。接着我们就可以利用前面的过程去寻优。这个寻优过程是一个叠代过程,中止条件一般为设置为达到最大循环数或者最小错误。
PSO中并没有许多需要调节的参数,下面列出了这些参数以及经验设置:
粒子数:一般取 20–40,其实对于大部分的问题10个粒子已经足够可以取得好的结果,不过对于比较难的问题或者特定类别的问题,粒子数可以取到100 或 200。
粒子的长度:这是由优化问题决定,就是问题解的长度。
粒子的范围:由优化问题决定,每一维可以设定不同的范围。
Vmax:最大速度决定粒子在一个循环中最大的移动距离,通常设定为粒子的范围宽度。例如上面的例子里,粒子,x1属于[-10,10],那么Vmax的大小就是20。
学习因子:c1和c2通常等于2,不过在文献中也有其他的取值。但是一般c1等于c2并且范围在0和4之间。
中止条件:最大循环数以及最小错误要求。例如,在神经网络训练例子中,最小错误可以设定为1个错误分类,最大循环设定为2000,这个中止条件由具体的问题确定。
全局PSO和局部PSO:前者速度快不过有时会陷入局部最优,后者收敛速度慢一点不过很难陷入局部最优。在实际应用中,可以先用全局PSO找到大致的结果,再用局部PSO进行搜索。
另外的一个参数是惯性权重,Shi 和Eberhart指出(A modified particle swarm optimizer,1998):当Vmax很小时(对schaffer的f6函数,Vmax=3),使用权重w=0.8较好。如果没有Vmax的信息,使用0.8作为权重也是一种很好的选择。惯性权重w很小时偏重于发挥粒子群算法的局部搜索能力;惯性权重很大时将会偏重于发挥粒子群算法的全局搜索能力。
实现C++代码代码来自2008年数学建模东北赛区B题,
#include"stdafx.h"#include#include#include#includeusingnamespacestd;intc1=2;//加速因子intc2=2;//加速因子doublew=1;//惯性权重doubleWmax=1;//最大惯性权重doubleWmin=0.6;//最小惯性权重intKmax=110;//迭代次数intGdsCnt;//物资总数intconstDim=10;//粒子维数intconstPNum=50;//粒子个数intGBIndex=0;//最优粒子索引doublea=0.6;//适应度调整因子doubleb=0.5;//适应度调整因子intXup[Dim];//粒子位置上界数组intXdown[Dim]=;//粒子位置下界数组intValue[Dim];//初始急需度数组intVmax[Dim];//最大速度数组classPARTICLE;//申明粒子节点voidCheck(PARTICLE&,int);//约束函数voidInput(ifstream&);//输入变量voidInitial();//初始化相关变量doubleGetFit(PARTICLE&);//计算适应度voidCalculateFit();//计算适应度voidBirdsFly();//粒子飞翔voidRun(ofstream&,int=2000);//运行函数classPARTICLE//微粒类{public:intX[Dim];//微粒的坐标数组intXBest[Dim];//微粒的最好位置数组intV[Dim];//粒子速度数组doubleFit;//微粒适合度doubleFitBest;//微粒最好位置适合度};PARTICLEParr[PNum];//粒子数组intmain()//主函数{ofstreamoutf("out.txt");ifstreaminf("data.txt");//关联输入文件inf>>GdsCnt;//输入物资总数Input(inf);Initial();Run(outf,100);system("pause");return0;}voidCheck(PARTICLE&p,intcount)//参数:p粒子对象,count物资数量{srand((unsigned)time(NULL));intsum=0;for(inti=0;iXup)p.X=Xup;elseif(p.XVmax)p.V=Vmax;elseif(p.Vcount){p.X[rand()%Dim]--;sum=0;for(inti=0;iXup)p.X=Xup;elseif(p.XVmax)p.V=Vmax;elseif(p.VXup;for(inti=0;i>Value;}voidInitial()//初始化数据{GBIndex=0;srand((unsigned)time(NULL));//初始化随机函数发生器for(inti=0;i
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号