

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
信息瓶颈(英语:information bottleneck)是信息论中的一种方法,由纳夫塔利·泰斯比、费尔南多·佩雷拉(Fernando C. Pereira)与威廉·比亚莱克于1999年提出。
简介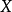 信息瓶颈(英语:information bottleneck)是信息论中的一种方法,由纳夫塔利·泰斯比、费尔南多·佩雷拉(Fernando C. Pereira)与威廉·比亚莱克于1999年提出1。
信息瓶颈(英语:information bottleneck)是信息论中的一种方法,由纳夫塔利·泰斯比、费尔南多·佩雷拉(Fernando C. Pereira)与威廉·比亚莱克于1999年提出1。
对于一随机变量,假设已知其与观察变量 Y之间的联合概率分布p(X,Y)。此时,当需要概括(聚类){\displaystyle X}时,可以通过信息瓶颈方法来分析如何最优化地平衡准确度与复杂度(数据压缩)。该方法的应用还包括分布聚类(distributional clustering)与降维等。
此外,信息瓶颈也被用于分析深度学习的过程。
信息瓶颈方法信息瓶颈方法中运用了互信息的概念。假设压缩后的随机变量为 T,我们试图用 T代替 X来预测 Y。
此时,可使用以下算法得到最优的T:
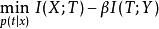
其中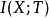 与
与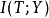 分别为X与T之间、以及T与Y之间的互信息,可由 p(X,Y)计算得到。
分别为X与T之间、以及T与Y之间的互信息,可由 p(X,Y)计算得到。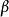 则表示拉格朗日乘数。
则表示拉格朗日乘数。
信息瓶颈:网络在抽取相关性时的理论边界2015年,Tishby和他的学生Noga Zaslavsky假设深度学习是一个信息瓶颈过程,尽可能地压缩噪声数据,同时保留数据所代表的信息2。Tishby和Shwartz-Ziv对深度神经网络的新实验揭示了瓶颈过程如何实际发生的。在一种情况下,研究人员使用小型神经网络,使用随机梯度下降和BP,经过训练后,能够用1或0(也即“是狗”或“不是狗”)标记输入数据,并给出其282个神经连接随机初始强度,然后跟踪了网络在接收3000个样本输入数据集后发生了什么。
实验中,Tishby和Shwartz-Ziv跟踪了每层网络保留了多少输入中的信息和输出标签中的信息。结果发现,信息经过逐层传递,最终收敛到信息瓶颈的理论边界:也就是Tishby、Pereira和Bialek在他们1999年论文中推导出的理论界限,代表系统在抽取相关信息时能够做到的最好的情况。在这个边界上,网络在没有牺牲准确预测标签能力的情况下,尽可能地压缩输入。
深度学习中的信息瓶颈问题信息瓶颈理论认为,网络像把信息从一个瓶颈中挤压出去一般,去除掉那些含有无关细节的噪音输入数据,只保留与通用概念(general concept)最相关的特征。Tishby和他的学生Ravid Shwartz-Ziv的最新实验,展示了深度学习过程中这种“挤压”是如何发生的(至少在他们所研究的案例里)。
Tishby的发现在AI研究圈激起了强烈的反向。Google Researc的Alex Alemi说:“我认为信息瓶颈的想法可能在未来深度神经网络的研究中非常重要。”Alemi已经开发了新的近似方法,在大规模深度神经网络中应用信息瓶颈分析。Alemi说,信息瓶颈可能“不仅能够用于理解为什么神经网络有用,也是用于构建新目标和新网络架构的理论工具”。
另外一些研究人员则持怀疑态度,认为信息瓶颈理论不能完全解释深学习的成功。但是,纽约大学的粒子物理学家Kyle Cranmer——他使用机器学习来分析大型强子对撞机的粒子碰撞——表示,一种通用的学习原理(a general principle of learning),“听上去有些道理”。
深度学习先驱Geoffrey Hinton在看完Tishby的柏林演讲后发电子邮件给Tishby。“这简直太有趣了,”Hinton写道:“我还得听上10,000次才能真正理解它,但如今听一个演讲,里面有真正原创的想法,而且可能解决重大的问题,真是非常罕见了。”
Tishby认为,信息瓶颈是学习的一个基本原则,无论是算法也好,苍蝇也罢,任何有意识的存在或突发行为的物理学计算,大家最期待的答案——“学习最重要的部分实际上是忘记”。
本词条内容贡献者为:
程鹏 - 副教授 - 西南大学
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号