

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
均值池化(mean-pooling)即对局部接受域中的所有值求均值。
介绍常用的池化方法有最大池化(max-pooling)和均值池化(mean-pooling)。根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
例子假设pooling的窗大小是2x2, 在forward的时候啊,就是在前面卷积完的输出上依次不重合的取2x2的窗平均,得到一个值就是当前mean pooling之后的值。backward的时候,把一个值分成四等分放到前面2x2的格子里面就好了。如下:
forward: [1 3; 2 2] -> [2];
backward: [2] -> [0.5 0.5; 0.5 0.5].
基于序的平均池化基于序的平均池化的动机是解决平均池化和最大池化容易损失大量有用信息的问题。最大池化将池化域内非最大激活值全部舍弃导致了严重的信息损失1。同样地,平均池化取池化域内的所有激活值进行平均,高的正的激活值可能和低的负的激活值相互抵消,从而导致判别性信息损失。基于序的平均池化方法解决这个问题通过取前
t 个数值最大的激活值进行平均。在池化域内,这前 t 个激活值的权重系数设为 1/t 其他的激活值的权重系数设为
0。因此,池化的结果可以通过下面的公式获得:
 t 表示选择参与池化的激活值的序位阈值。
t 表示选择参与池化的激活值的序位阈值。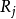 表示在第 j 个特征图内的池化域,i表示在这个池化域内激活值的索引值。
表示在第 j 个特征图内的池化域,i表示在这个池化域内激活值的索引值。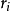 和
和 分别表示激活值 i 的序位和激活数值。
分别表示激活值 i 的序位和激活数值。
t 的取值不应太大,也不应太小,因为当 t =1时基于序的平均池化退化为最大池化,当t=n 时退化为平均池化.t 的取值应该能够保证基于序的平均池化提供一个好的折中在最大池化和平均池化之间。不同的视觉任务,t 的取值是不同的,但是经验发现当 t 取中值时一般取得满意的结果。
基于序的池化方法将低的或者负的激活值排斥在外,仅仅使得具有高响应值的激活值参与平均操作。该方法能够保留重要的信息,而将无用的信息舍弃,有利于深度卷积神经网络性能的提升。
本词条内容贡献者为:
李岳阳 - 副教授 - 江南大学
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号