

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
双向区组亦称二维区组。按两个不同标志或按同一标志在两个不同方向上划分的区组。拉丁方、尤登方、格子方等区组,都是双向区组。
基本介绍双向区组,在—个方向上的区组作为一维区组称做“行区组”,在另—方向上的区组作为一维区组,称做“列区组”。如,农田试验按肥力对田地在两个方向上的区组,可以形象地表示为
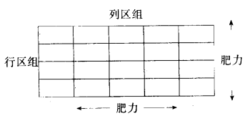
其中每行和每列的几个小区构成行区组和列区组。
同样可以考虑多向区组。按一个标志划分的区组称做“单向区组”。单向和多向区组的区别在于,前者各小区的条件相同,而后者则不然。随机化区组和不完全区组都是单向区组1。
实验设计农业试验一般是田间试验,受环境条件的影响较大,其中土壤差异是最重要的影响因素,故田间试验设计将区组分为纵向区组和横向区组,从而控制纵横两个方向的土壤差异,提高试验的精确度。
双向区组作因素的设计
1.设计方法
设试验中有k个因素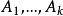 ,其对应水平数分别为
,其对应水平数分别为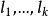 ;又有2个方向的随机区组A、B,分别对应有d1、d2个状态,为表达方便,不妨假设k个因素为定量变量,随机区组A、B为定性变量。我们以混合型均匀设计表中选出带有s=k+2列的
;又有2个方向的随机区组A、B,分别对应有d1、d2个状态,为表达方便,不妨假设k个因素为定量变量,随机区组A、B为定性变量。我们以混合型均匀设计表中选出带有s=k+2列的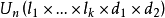 均匀表,可假设表中前k列对应k个连续变量;表中后2列可安排区组因素,并要求n>k+d+1,其中
均匀表,可假设表中前k列对应k个连续变量;表中后2列可安排区组因素,并要求n>k+d+1,其中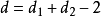 。试验设计如表1,为保证此两因素为完全试验的组合,可通过拟水平方法对区组水平作相应的处理,然后安排n个试验,得到n个结果
。试验设计如表1,为保证此两因素为完全试验的组合,可通过拟水平方法对区组水平作相应的处理,然后安排n个试验,得到n个结果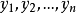 。
。
|| || 表1 双向随机区组的设计格式
2.试验数据的统计分析
与处理单区组因素的统计分析方法一样,首先进行数量化处理,将2个区组因素之状态,分别化成(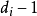 )个相对独立的伪变量
)个相对独立的伪变量 ,其中i=1,2.将这总共d=d1+d2-2个伪变量与相应的k个定量变量
,其中i=1,2.将这总共d=d1+d2-2个伪变量与相应的k个定量变量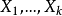 ,一起建立多元回归方程。为此,要注意对均匀设计表进行挑选,以保证各类效应不蜕化。根据实际需要可考虑建立以下模型:
,一起建立多元回归方程。为此,要注意对均匀设计表进行挑选,以保证各类效应不蜕化。根据实际需要可考虑建立以下模型:
1)一阶线性模型,即考察如下的回归方程:
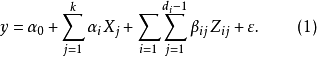 解出回归系数,找出最佳状态组合,并算出最大估计值。
解出回归系数,找出最佳状态组合,并算出最大估计值。
2)二次响应曲面模型(考虑一些交互效应,和一些连续变量的高次效应)。考察如下的回归方程
 通过数据分析,在试验结果的变异中剖分出横向区组、纵向区组、组合处理问的变异以及随机误差的变异,并找出优化的因素组合2。
通过数据分析,在试验结果的变异中剖分出横向区组、纵向区组、组合处理问的变异以及随机误差的变异,并找出优化的因素组合2。
实例1 为了解2种肥料对某一新作物的影响,通过试验找出它们适宜肥料拌种的方法与用量,摸索增产规律。种子拌肥量的水平如下:X1磷肥(g/单位面积)分为12个水平:{200,220,240,260,280,300,320,340,360,380,400,420};X2腐植酸铵(g/单位面积)分为6个水平:{200,240,280,320,360,400}。
考虑土地的差异设置横向B(4块)和纵向A(3块),选用的均匀设计表如表2,根据表2均匀表前4列安排试验,得到的试验结果如表3。
|| || 表3 U₁₂(12×6×4×3²×2²)均匀表

考虑变量 ,用SAS软件包求解建立回归方程为:
,用SAS软件包求解建立回归方程为:

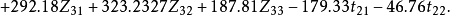
F=2 021.757>F0.01,差异极显著。由上式可求得最佳状态组合为X1=371.4,X2=400,B取1,A取3,此时可获最大估计值3。
本词条内容贡献者为:
刘军 - 副研究员 - 中国科学院工程热物理研究所
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号