

科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-11-17
全模型(Full Model)也称为饱和模型(Saturated Model),指包含所有自变量的线性回归模型。在对回归模型进行一般线性检验时,需要先拟合一个全模型,并计算其残差平方和。然后再拟合一个不包括欲检验参数的线性回归模型,通常称作简模型或选模型,也计算出其残差平方和,通过全模型和简模型的残差平方和之差进行有关参数的检验1。
基本介绍设有一个因变量Y和m个自变量 构成的线性回归模型为:
构成的线性回归模型为:
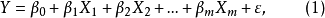 由于该模型是因变量Y与所有自变量之间的回归模型,故称为全模型。实际应用中,有时,尤其是当m较大时,我们可能会舍弃一些变量,只用其中一些自变量建立回归方程,如从所有可供选择的m个自变量中选择其中p个,为了方便起见,我们不妨认为所选择的p个自变量就是
由于该模型是因变量Y与所有自变量之间的回归模型,故称为全模型。实际应用中,有时,尤其是当m较大时,我们可能会舍弃一些变量,只用其中一些自变量建立回归方程,如从所有可供选择的m个自变量中选择其中p个,为了方便起见,我们不妨认为所选择的p个自变量就是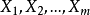 中的前p个,记为
中的前p个,记为 ,这样由所选的p个自变量建立的回归模型为:
,这样由所选的p个自变量建立的回归模型为:

我们称其为选模型2。
自变量选择对估计和预测的影响我们可以将上面关于自变量的选择问题看成是选用全模型还是选模型去描述一个实际问题。如果应该用全模型描述实际问题,而我们却选择了选模型,则说明我们在建立模型时就丢掉了一些有用的自变量;反之,如果应该用选模型,而我们却使用了全模型,则说明我们将一些不必要的自变量引进了模型。两种情况都属于因自变量而导致的模型设定的错误。那么,模型自变量选择的不当会给参数估计或模型的应用(如对因变量的预测)带来什么影响呢2?
为了方便起见,我们把模型(1)的参数向量 和随机误差项
和随机误差项 的估计量记为:
的估计量记为:
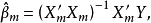
 模型(2)的参数向量和的估计量记为:
模型(2)的参数向量和的估计量记为:
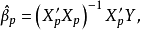
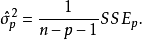
1)若已知全模型正确而误用了选模型,当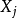 与
与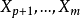 的相关系数不全为零时,则选模型的回归系数的最小二乘估计是全模型相应参数的有偏估计。
的相关系数不全为零时,则选模型的回归系数的最小二乘估计是全模型相应参数的有偏估计。
2)若已知全模型正确,当给定新的自变量值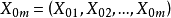 时,因变量的估计值为:
时,因变量的估计值为:
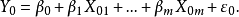 但若误用了选模型,则Y的估计值为:
但若误用了选模型,则Y的估计值为:
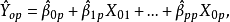 该预测值是
该预测值是 的有偏估计,即
的有偏估计,即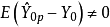 。这表明,如果全模型正确,而我们舍掉了m-p个自变量,用剩下的p个自变量建立回归模型,则参数估计值是全模型的相应参数的有偏估计,用其进行预测,预测值也是有偏的。
。这表明,如果全模型正确,而我们舍掉了m-p个自变量,用剩下的p个自变量建立回归模型,则参数估计值是全模型的相应参数的有偏估计,用其进行预测,预测值也是有偏的。
3)从预测的残差来看,选模型的预测残差为:
 而全模型的残差为:
而全模型的残差为:
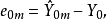 其中
其中
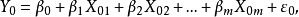 则
则 。可以看到,尽管选模型所做的预测是有偏的,但是得到的预测残差的方差下降了。
。可以看到,尽管选模型所做的预测是有偏的,但是得到的预测残差的方差下降了。
4)如果选模型正确,从无偏性的角度看,选模型的预测值为:
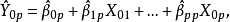 是因变量的某一值
是因变量的某一值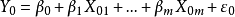 的无偏估计。此时,全模型的预测值
的无偏估计。此时,全模型的预测值 则是
则是 的有偏估计。
的有偏估计。
从预测方差的角度看,选模型的预测方差小于全模型的预测方差。从均方预测误差的角度看,全模型的均方误差包含预测方差和预测偏差的平方两部分,而选模型的均方误差仅包含预测方差这一项,且小于全模型,因而全模型的预测误差将会更大。
可见,一个好的回归模型,并不是考虑自变量越多越好或精度越高越好。在建立回归模型时,选择自变量的基本指导思想是少而精。有时可能漏掉了一些对因变量Y还有些影响但影响并不十分大的自变量,这时由于选模型估计的回归系数的方差,要比由全模型所估计的相应变量的回归系数的方差小。此外,对于所预测的因变量的方差来说也是如此,少了一些对因变量y有影响的自变量后,会导致估计量是有偏的。然而,尽管估计量是有偏的,但其预测偏差的方差会下降。
如果保留下来的自变量中有些对因变量不太重要,那么方程中包括这些变量就会导致模型参数的估计和因变量预测的有偏性与精度的降低。因此,建立回归模型时,应尽可能剔除那些可有可无的自变量2。
本词条内容贡献者为:
刘军 - 副研究员 - 中国科学院工程热物理研究所
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号