

宫奥博
加好友
宫奥博 2021-05-08

美国莱斯大学计算机系助理教授 Anshumali Shrivastava
深度神经网络(deep neural networks,DNN)是人工智能的有力工具,在某些任务上的表现甚至已经超越人类专家的水平。对这类网络的训练,可以看作是一系列矩阵运算操作,特别适合交给 GPU 运算,它们运算效率远高于 CPU,但是成本仅仅是 CPU 的 3 倍。
但是现在,情况已有所不同。
近日,来自美国莱斯大学(Rice University)的计算机科学家们证实,一种基于 CPU 的深度神经网络训练算法的训练速度远超过 GPU 算法,最高速度比后者快 15 倍。
论文名为 Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More 。该工作的突出贡献在于,提供了在现代 CPU 上实现深度学习的随机算法的几个新视角。
正如作者之一、莱斯大学助理教授 Anshumali Shrivastava 所说:“当前,训练成本问题是人工智能的现实瓶颈。一些公司每周花费上百万美元用于训练和微调神经网络…… 整个工业界都把目光集中于一类改进 —— 加速矩阵操作。大家都在寻找专用硬件和架构加速矩阵运算,甚至开始探讨堆叠专用硬件来适应某一个深度学习模型。
但是,如果我们把目光稍稍移开,将注意力放回到算法上,可以一切都会不同。”
SLIDE 算法
早在 2019 年,Shrivastava 的实验室团队就开始了算法层面加速深度学习训练的努力,他们将深度神经网络的训练问题转化为搜索问题,使用哈希表解决。
他们的 “次线性深度学习处理引擎”(sub-linear deep learning engine, SLIDE)是专门根据 CPU 设计的,是一种基于 C++ 实现的、在 CPUs 上比 GPUs 更快地训练深度神经网络的算法。该算法克服了 AI 领域产业发展的一个主要障碍,有力证明了在不依赖于 GPUs 等专业级加速硬件的情况下,依旧可以实现对深度学习技术的加速。
SLIDE 结合了智能哈希随机算法和 CPU 上中等规模的多核并行性,这种思路遵循自适应稀疏 /dropout 的路线,根据神经元的激活情况,只需更新一小部分神经元,便可以精确地训练神经网络。
尤其是,SLIDE 采用局部敏感哈希(LSH, Locality Sensitive Hash)方法自适应地识别每次更新过程中的神经元。目前 SLIDE 已被证明,在训练数以百万计的参数神经模型方面要比 GPU 更快。
在本文中,团队认为目前 SLIDE 的实现并未发挥其最佳性能,因为缺少现代 CPU 的助力。研究的重点便是优化 X86 架构的现有 SLIDE 实现。特别的是,团队展示了借助 AVX(Advanced Vector Extensions)-512 指令集,SLIDE 的计算是如何进行向量化的。
此外,团队还强调了不同类型的内存优化和量化的机会。也就是说,他们坚定地认为,如果将所有这些方法结合起来,可以在相同的硬件下,实现高达 7 倍的计算速度。
为了验证上述假设,团队将实验专注于大型的推荐和 NLP 模型上。
在两台Intel最近推出的两款不同的CPU服务器上评估了优化的SLIDE系统及其有效性,分别是Cooper Laker服务器(CPX)和Cascade Lake服务器(CLX),并与5个基准进行了对照。
这两种处理器的相同之处是都支持VX-512指令。而差异在于,只有CPX机器支持bloat16。两者的具体架构如下:
CPX是新的第三代Intel Xeon可扩展处理器,支持基于VX512的BF16指令。它拥有Intel x86_64架构,4个28核CPU总共112个核,能够与超线程并行运行224个线程。L3缓存大小大约为39MB,L2缓存约为1MB。
CLX是不支持BF16指令的“老一辈”可扩展处理器。它采用Intel x86 64架构,具有双24核处理器(Intel Xeon Platinum 8260L CPU @ 2.40GHz)总计48核。使用超线程,可以运行的并行线程的最大数量达到96。L3缓存大小约为36MB,L2缓存约为1MB。
对比的基准展示如下:
l V100 GPU上的full-softmax tensorflow 实现;
l CPX上的full-softmax tensorflow 实现;
l CLX上的full-softmax tensorflow 实现;
l CPX上的Naive SLIDE;
l CLX上的Naive SLIDE。
结果显示,就 wall lock time 而言,SLIDE 在中等的 CPU 上训练一个约 2 亿参数的神经网络,比在 NVIDIA V100 GPU 上优化的 TensorFlow 实现要快得多。而且最令人兴奋的是,SLIDE 相比其他基线而言,可以更快达到任意的精度水平。
大量的优化空间
与未优化的 SLIDE 相比,在同样的硬件基础上,团队采用的优化工作可以使训练时间提高 2-7 倍。这一系列优化工作包括:
内存合并技术(Memory Coalescing)和缓存利用率:
大多数机器学习任务都与内存相关联。它们需要批量读取连续地数据,然后更新存储在主存中的大量参数。SLIDE 实现的情况也类似。
了解 CPU 中的内存加载机制:
当所有线程执行一个加载指令时,最有利的方案是让所有线程访问连续的全局内存位置。在这种情况下,硬件可以将这些内存访问合并为对连续 DRAM 位置的单个访问。因此,大多数线程都直接从缓存加载,这至少是从 DRAM 加载速度的 3 倍。然而,包括 SLIDE 在内的大多数随机算法都忽略了这一现象,因为它们假定内存访问模式是随机的,足以利用缓存。团队成员发现 SLIDE 有主要的内存碎片(memory fragmentation),这无疑增加了数据访问延迟 —— 碎片内存会降低 CPUs 上的高速缓存利用率。SLIDE 中的内存碎片存在两个显著的原因:(1)数据内存碎片和(2)参数内存碎片。
删除数据内存碎片:
SLIDE 使用稀疏数据集和稀疏激活。考虑到非零(non-zeros)的变量数目,通常采用的选择是使用不同的数组(或向量)来存储各种数据实例。但是,这会导致不必要的缓存丢失。SLIDE 使用了 HOGWILD 风格的并行模式,其中多个不同的线程同时处理数百个数据实例。使用 SLIDE 中的稀疏格式的标准实现,每个线程将访问来自完全不同的 DRAM 内存位置的数据,这不会利用缓存,特别是跨所有线程共享的 L3 缓存。
团队使用的方法并未分割每个数据实例,而是创建一个长连续向量,连续存储一批数据实例的非零索引和值。为了跟踪非零的变量个数,需要保留其他偏移量。这些偏移值将用于直接索引任何数据实例的起始位置。在实际应用中,常常使用数百个线程并行处理数百到数千个数据实例。因此,当从 DRAM 中查找第一个数据实例时,批处理中的大多数连续数据元素都被加载 / 预取(loaded/pre-fetched)进来。
删除参数内存碎片:
在 SLIDE 算法中,每一层的每个神经元都被独立激活,激活神经元的身份依赖于输入。因此,每个输入实例都通过查询哈希表来动态选择神经元。非常高的稀疏性(作为 SLIDE 算法的关键优势)通常会确保两个不同的线程选择一组几乎 “毫无瓜葛” 的神经元。然而,在复杂的多核环境中,数百个数据批被并行处理,产生大量的经过处理的神经元。因此,在每个批处理中可能需要几个相邻的神经元。这种现象为内存合并技术(Memory Coalescing)创造了另一个机会。在此阶段,团队确保即使神经元是独立的实体,同一层的神经元权值在主存中是连续的,以提高缓存效率。需要注意的是,团队保留了一大块的连续内存,其中包含给定层中的不同神经元权重。
超线程(HT, Hyper-Threading)用于 HOGWILD 风格更新:
超线程允许处理器从实际上来加倍其核数,并同时执行两倍多的线程,在线程之间来回跳转,在另一个线程停止时执行指令。因为 SLIDE 梯度更新是 HOGWILD 风格的数据并行和异步,所以超线程提供了一个显著的提升。由于 SLIDE 内存访问的随机特性,线程确实会因为缓存错过而停止。从这一点上看,超线程确实是有利的,因为另一个线程可以利用等待时间来处理不同的数据实例。
用 AVX-512 进行向量化:
摩尔定律(Moore's Law)通过额外的内核和更宽的 SIMD(单指令,多数据)寄存器持续提供更高的并行性,从而确保了在几代硬件上的性能改进。AVX(Advanced Vector Extensions)-512 是针对 x86 集架构的 512 位 SIMD 指令的更新版本。要执行 CPU 指令,如加法、乘法等,操作值必须加载到寄存器中。超时寄存器的大小已经增加,允许更大值的存储和操作,并允许多个值存储在单个更宽的寄存器中。这是为进行向量化,后来扩展出来的功能。现在大多数 CPUs 都包含 64 位寄存器,但是一些较新的处理器则包含多达 512 位的寄存器。该系统使用 AVX-512 指令,其指令允许对驻留在 512 位寄存器中的值的 “向量” 进行单个操作,如加法操作等。简单举例来说,假设希望对两个数组进行成对加法,每个数组包含 16 个 32 位整数。在这种情况下,便可以考虑将每个数组加载到 512 位寄存器中,并利用单个操作将它们相加,然后将产生的结果值返回到一个新数组中。图 2 给出了示例。

SLIDE 中的 AVX-512:
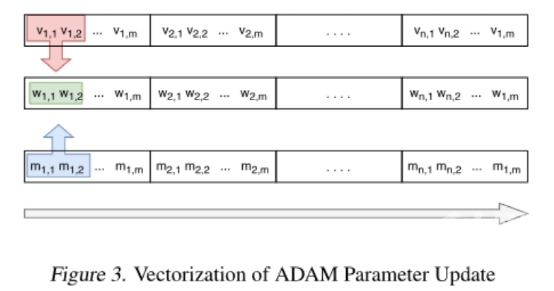
向量化 ADAM 参数更新是一件非常简单的任务。根据标准向量公式来更新权重矩阵中的每一项。鉴于所有的矩阵都表示为连续的内存块,因此可以将此过程从 2D 循环简化为 1D 循环。从本质上而言,就是取了一个 1D 循环,以 16 或 32 的增量遍历内存中的数组(假设权重表示为 32 位或 16 位浮点数)。图 3 给出了对速度、动量和梯度更新进行向量化的示例。
哈希计算:
SLIDE 中一个重要的计算瓶颈就是哈希计算。SLIDE 使用 LSH 对高激活神经元进行采样。特别是,SLIDE 使用了最近提出的 DTWA 哈希算法,该算法可以很好地处理稀疏数据。为了有效地向量化这个 LSH 函数,团队成员预先计算了所有索引的随机映射。然后,使用标准的 AVX-512 向量化指令,对每个 bin 中的最大操作进行聚合。
BF16 优化:
脑浮点格式(BF16, Brain floating-point format)使用计算机内存中的 16 位来表示一个浮点数。它已在硬件加速机器学习中得到了广泛应用。与 FP32 相比,BF16 将尾数从 23 位截断到 7 位,同时保留了 8 位的指数。团队提出了两种利用 BF16 加速训练过程的模式。具体地,第一种模式是用 BF16 格式表示激活和权重。第二种模式表示在 BF16 中激活,同时更新 FP32 中的参数,以避免在提高速度的同时降低训练质量,主要是考虑到用 16 位操作替换 32 位操作可能会提高计算速度。与此同时,它还通过对相同数量的指令加倍操作次数来增强了 AVX-512 的性能。
实验和分析
团队成员在三个真实的公共数据集上评估了框架和其他基线模型:Amazon670K(用于推荐系统的 Kaggle 数据集)、WikiLSH-325K 数据集和 Text8(NLP 中的数据集)。详细统计数据见下表 1:

在图 6 中,团队展示了所有方法在挂钟训练时间和 P@1(Precision@1)方面的性能。结果显示了该团队提出的优化 SLIDE 在 CPX 和 CLX(深绿色和浅绿色)上训练时间均优于其他基准。其中,首行(Top row)代表所有数据集的时间收敛图,而底行(Bottom row)显示了所有数据集的柱状图。

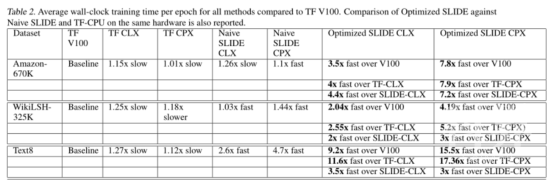
下表 2 提供了三个数据集上的详细数值结果:
下表 3 中,研究者展示了 BF16 指令对每个 epoch 平均训练时间的影响。结果表明,在 Amazon-670K 和 WikiLSH325K 上,激活和权重中使用 BF16 指令分别将性能提升了 1.28 倍和 1.39 倍。然而,在 Text8 上使用 BF16 没有产生影响。

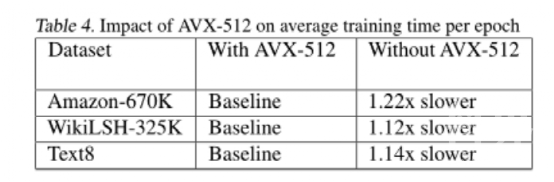
下表 4 展示了在有无 AVX-512 的情况下,优化 SLIDE 在三个数据集上的每个 epoch 平均训练时间对比。结果表明,AVX-512 的向量化将平均训练时间减少了 1.2 倍。由于运行计算相同,因此数据集的准确性保持不变。
这支研究团队真诚希望,这项工作能够激发更多关于新算法及其优化 CPU 实现的更多研究,以用于大规模深度学习工作负载。
“基于哈希表的加速策略已经超越了 GPU,但是 CPU 还在继续进步”,本研究的学生作者、莱斯大学研究生 Shabnam Daghaghi 说,“我们利用 CPU 的先进技术加强 SLIDE。我们想说明,如果你不再拘泥于加速矩阵运算,你可以利用现在 CPU 的力量,以 15 倍的速度训练人工智能模型。”
今天,CPU 仍是最普遍存在的计算硬件,设计适合于 CPU 的 AI 算法,这类研究或许应该受到更多的重视。
Reference:
1、https://arxiv.org/abs/2103.10891
2、https://github.com/RUSH-LAB/SLIDE
数据 算法 内存 深度神经网络 计算机指令 线程 cpu时间 cpu参数 指令 内存碎片

深度学习神经网络方法获改进

对X射线衍射小型数据集分类—数据增强-深度神经网络

npj: 电镜中的垃圾变黄金—深度神经网络

人工智能、深度学习、神经网络、大数据备忘录

深度神经网络加速器体系结构概述

解读丨为什么说卷积神经网络,是深度学习算法应用最成功的领域之一?

【速览】TPAMI 2019 | 正交深度神经网络
快速指令集计算机
精简指令集计算机操作系统

数据时代,别忘捂紧“信息钱袋”
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号