

宫奥博
加好友
宫奥博 2021-06-02
设计出色的 CPU 或 GPU,甚至是 FPGA 或定制 ASIC(如交换机或路由器芯片),是创建更强大系统的一个重要方面。但是,如何把这些器件分解成小芯片以提高产量和降低成本,并在一个封装内以及跨封装和节点将其组合在一起同样重要。
本周在台湾举行的 Computex 大会上,AMD 展示了其在芯片工艺和芯片封装方面的一些实力,以及这两个领域的进步如何成为 AMD 在所有高性能计算市场扩张的关键,而不仅仅是模拟和建模。
“在AMD,我们一直在思考下一步是什么,”该公司首席执行官 Lisa Su 在她的 Computex 主题演讲中解释说。“先进技术是我们产品领先地位的关键基础,这意味着将最好的工艺技术与最好的封装技术结合在一起。我们是台积电 7 纳米先进制造技术的早期采用者,到目前为止,我们已经在所有市场上交付了 30 多种 7 纳米产品。我们的 5 纳米技术路线图正在走上正轨,包括我们将于明年推出的首款 Zen 4 产品。”
Lisa Su提醒大家,AMD也一直走在芯片封装技术的前沿,我们一直认为这与芯片设计和芯片工艺同等重要。您必须同时擅长这三项才能取得成功——或者与那些从事初级研究的人合作,并将其开发成您将需要的未来技术。IBM 曾经擅长这三个方面,回到今天,AMD 在研究各种芯片封装方面做得很好,同时密切关注它曾经参与的芯片工艺进步在 2009 年初分拆 GlobalFoundries 之前。
“我们也是先进封装技术的领导者,”Lisa Su说。“我们在封装创新方面的投资是一个多年、多技术的旅程。2015 年,AMD 向 GPU 市场推出了高带宽内存(HBM)和硅中介层技术,在小尺寸内存带宽方面领先业界。然后,我们在 2017 年推出大容量多芯片模块封装时,为数据中心和 PC 市场的计算设定了新的性能轨迹。2019 年,我们推出了小芯片,在同一封装中为 CPU 内核和 I/O 使用不同的工艺节点,从而显着提高了性能和功能。”
芯片更稳固地进入第三维总是迟早的事情。芯片并不是真正的平面物体、2D 物体,而是堆叠了数十层材料来创建晶体管和电路。但最终,由于光刻设备掩模版尺寸的限制,与在同一区域制造许多小芯片的成本相比,制造大芯片的成本高(小芯片的产量在统计上更好,因此获得一定数量的原始计算所需的晶圆更小,从而降低了成本),我们都知道我们将采用 2.5D(通过中介层将芯片相互连接到全 3D 堆叠裸片以创建具有各种好处的更紧凑的设备。
这就是Lisa在她的主题演讲中暗示 AMD 要去的地方:往上发展。
Lisa Su 展示的生产芯片是带有 3D V-Cache 的 Ryzen 5900X CPU,每个 CCD 具有 96 MB 缓存,在具有 12 或 16 核的 Ryzen 处理器复合体中总共有 192 MB 的三级缓存。这就是这里显示的内容:
在运行 Gears V 视频游戏的基准测试中,普通的 Ryzen 9 5900X 可以驱动 184 FPS,而带有 3D V-Cache 的原型 Ryzen 5900X 可以驱动 206 FPS。两者都具有相同的核心数(未指定)并且都以相同的 4 GHz 时钟速度运行;这使 Gears V 的性能提高了 12%。在一系列游戏中,平均性能提高了 15%。正如 Su 所说的那样,这是一种性能提升,相当于 CPU 设计中的架构生成步骤——实际上不必更改 CPU 内核或 I/O 芯片。
苏说,台积电在AMD的大力帮助下打造的3D结构技术,其互连密度是2D小芯片的200倍以上,密度是其他3D堆叠技术的15倍。顺便说一下,这是一种完全没有焊料凸点的直接铜对铜线接合,与微凸点 3D 封装方法相比,这种 3D 结构技术每个信号的能效高出 3 倍以上。
“所有这些都使其成为世界上最先进、最灵活的有源硅堆叠技术,”她笑着补充道。
苏说,3D V-Cache将在今年年底量产。我们希望它很快能在服务器 CPU 上进行测试,也许今年晚些时候在橡树岭国家实验室安装的“Frontier”超级计算机中使用的“Trento”定制 CPU。

人们对 Trento 知之甚少,但人们普遍预计它是一个定制的“米兰”部件,采用与米兰使用的内核相同的内核,但将它们与新的 I/O 和内存小芯片结合在一起,该芯片在芯片上具有 Infinity Fabric 3.0 链接。端口,以及足够多的端口,以便单个插槽的 CPU 内存和四个 GPU 的内存可以全部链接到一个单一的、连贯的、共享的内存中。Oak Ridge 在作为“Summit”超级计算机基础的 IBM Power9 CPU-Nvidia Volta GPU 计算复合体中具有相干内存,而通过在 Power9 处理器上添加 NVLink 端口实现的这种相干性是使 IBM 和 Nvidia 赢得交易以构建 Summit 的架构。
AMD 3D Chiplet 技术:迎接处理器的未来
AMD 昨晚在Computex 2021主题演讲中发布了一些新闻,当时 AMD 首席执行官 Lisa Su 博士展示了该公司与台积电合作开发的新 3D 小芯片技术。
总而言之,与其将自己分散在更宽的芯片上,不如将逻辑单元和高速缓存等 CPU 组件堆叠在一起,利用垂直空间,而不是在一个芯片上增加总表面积扁平晶圆。
虽然该技术主要由台积电率先推出,但 AMD 似乎是第一家通过在其锐龙系列处理器中引入新的“垂直 L3 缓存”来利用新工艺的芯片制造商。
在没有过多陷入计算机系统架构的情况下,高速缓存是处理器的一部分,可以在任何给定时间为处理器存储最相关的数据和程序指令。缓存越大,可以存储的数据就越多,因此处理器不必从 RAM 中获取新数据,这需要更长的时间并降低性能。
根据 Su 的说法,通过将 64MB SRAM 节点堆叠到 CCD(处理器中包含一组处理核心的部分)上,AMD 能够将 16 核处理器上可用的 L3 缓存从最大 64MB 增加到 192MB .
虽然这项技术还没有进入消费级处理器,但AMD 表示,它“有望在今年年底前开始生产具有 3D 小芯片的未来高端计算产品。”
在没有深入摩尔定律的杂草的情况下,十多年来,我们的计算机将逐渐变得更快的假设已经被搁置了。我们不能再依靠越来越小的晶体管的蛮力工程来使我们的计算机越来越强大。在单个硅原子开始成为不可靠的电流介质之前,我们正在接近这些晶体管的字面物理极限。
因此,虽然我们已经完成了制造功能越来越强大的计算机的简单方法,但这并不意味着我们所知道的进步的结束。我们将在未来几年继续缩小晶体管的尺寸,但下一阶段正在超越晶体管并创新我们尚未考虑的新处理器技术——而 3D 制造显然是下一步。
我们很早就意识到,当您用完物理空间并且需要挤进更多东西时,无论是晶体管、库存还是人员,都会开始向上移动而不是向外移动。
AMD 的新 3D V-Cache 只是朝着这个方向迈进的第一个实现- 从字面上看。扩展可用于现有处理器架构的缓存已经大大提高了性能,但我们没有理由不也开始堆叠内核。
技术 处理器 晶体管 计算机 芯片 处理器技术 cpu时间 amd处理器

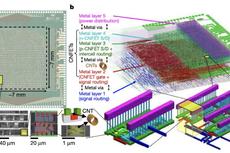
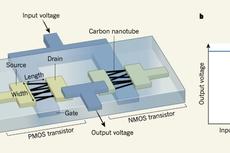
Nature:史上最大碳纳米管芯片问世!MIT用14000个碳纳米管晶体管造出16位微处理器
史上最大碳纳米管芯片问世!MIT用14000个碳纳米管晶体管造出16位微处理器


迄今最快AI芯片拥有4万亿个晶体管,将用于构建大型人工智能超级计算机

技术鸿沟是人工智能普及的最大障碍

流体晶体管面世,预示液态计算机时代或将到来
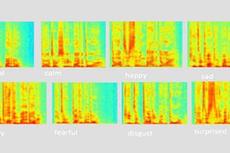
你的声音透露出高兴还是痛苦?计算机能识别情绪了

AMD锐龙5000G处理器开售
超薄晶体管让计算机芯片“再快一点”
国家技术转移体系建设有了“施工图”

史上最大碳纳米管芯片问世!MIT用14000个碳纳米管晶体管造出16位微处理器
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号