科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2020-01-16
来源:X一MOL资讯
非靶向代谢组学的数据分析,尤其是代谢物特征数据(metabolic features)的提取步骤,通常需要利用高通量分析软件来实现,例如XCMS、MZmine 2以及MS-DIAL。这些软件虽然对非靶向代谢组学的数据分析极为便利,但仅对基于高斯曲线的拟合识别代谢物特征数据有效,而对于不完全符合高斯曲线或者浓度较低的代谢物特征则可能造成数据丢失。目前,数据依赖型采集(data dependent acquisition)作为最常用的二级质谱数据采集方式,其将一部分数据采集时间用于采集二级质谱数据(MS/MS)。由于高斯曲线拟合仅使用一级质谱数据结果,而数据依赖型采集方式可能致使更多的代谢物特征数据无法拟合高斯曲线,进而引起更多的代谢物特征在数据分析过程中被忽略。而这些数据的丢失会影响代谢组学分析的完整性,因此,开发能够减少数据丢失,回收被忽略数据,最终降低代谢组分析中假阴性概率的数据处理方法具有重要的意义。
近日,英属哥伦比亚大学还涛课题组,开发了一种可以提高代谢组数据覆盖率(即降低代谢组分析假阴性概率)的新型综合代谢物特征数据提取策略(Integrated feature extraction strategy)。该策略在高斯曲线拟合提取代谢物特征数据的基础上,加入额外的MS/MS信息,以完善代谢组数据。由于传统高斯拟合方法会忽略一些峰形不好或信号较低的代谢物特征数据,而这些被忽略的特征数据大多包含MS/MS信息,且这些结构信息对代谢组数据分析至关重要。因此,该提取策略旨在回收被忽略的MS/MS信息,以识别更多代谢物特征数据,并提供代谢物的化学组成及结构等信息。此外,该研究进一步表明被忽略的MS/MS信息可用于代谢物的定量分析。最后,新的数据分析策略在真实的生物样品数据分析中得到验证。与传统分析软件相比,该分析策略将具有统计学意义的代谢物数据数据量提高24.4%,极大的减少了代谢组分析中假阴性情况的发生。
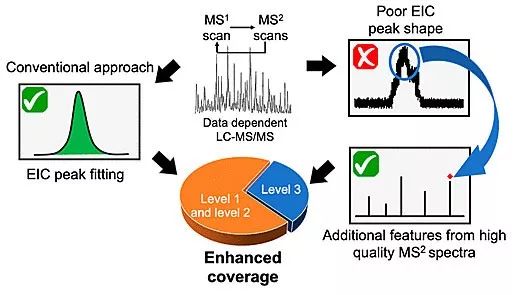
该成果发表在美国化学会旗下的Analytical Chemistry 上,英属哥伦比亚大学的博士后胡雅茜为第一作者,还涛助理教授为通讯作者。
原文(扫描或长按二维码,识别后直达原文页面):

Enhancing Metabolome Coverage in Data-Dependent LC–MS/MS Analysis through an Integrated Feature Extraction Strategy
Yaxi Hu, Betty Cai, Tao Huan
Anal. Chem., 2019, 91, 14433-14441, DOI: 10.1021/acs.analchem.9b02980
来源:X-molNews X一MOL资讯
原文链接:http://mp.weixin.qq.com/s?__biz=MzAwOTExNzg4Nw==&mid=2657627183&idx=5&sn=23f65e3099fe4ad81c8e5e152300692c&chksm=80f805ffb78f8ce969b25eb8e5b87491209fbb36f6c63b310e7198d8e219f8787b7d5b2e1361&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
2016制造业知识服务高峰论坛暨中国制造业知识服务联盟成立大会在北京举行



大数据分析平台为疫情防控保驾护航
第九届互联网与分布式计算系统国际会议在武汉举办



“疫”考之下,大数据分析被“摊平”的春运




MapGIS文本大数据分析与挖掘引擎

大数据分析贝多芬所用的音乐节拍器的奥秘

电信大数据分析支撑服务疫情防控阻击战
P53大数据分析:超10000例癌症分析带来新见解

大数据分析表明昆虫多样性与碳排放密切关联
第九届中国云计算大会·科猫邀你免费入场


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号