科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2019-09-29
来源:高分子科学前沿
互联网对生活的改变大家有目共睹,人工智能(AI)的发展也如火如荼。甚至人们提出了一个问题“将来是人类统治机器人还是机器人统治人类?”如果机器人在睡梦中都在优化算法,人类拿什么去抵抗可能的机器人入侵?虽然这个问题有点天马行空,但这折射出另一个问题,AI的发展已经有了革命性的突破,它不止是简单地改变普通人的生活方式,也深入到更加专业的领域,发挥更大的作用。机器人停车都算小儿科,说不定机器人看病、机器人搞科研都会成为现实。问题是,那时候,人类会扮演什么样的角色?越早想清楚这个问题可能越有利于今后的发展。《Science》近期就AI在各专业领域的应用和发展进行了报道:

据一些主流媒体报道,最近AI在世界各地出现,而这些新闻来源本身也越来越多地受计算机算法的驱动。营销人员利用AI定位广告,工程师利用它预测设备故障,而由AI驱动的社交媒体平台对从时尚到政治等的方方面面都施加着巨大的影响。在更广泛的领域,有一部分策略使用了人工神经网络。在这些模拟生物大脑中,组成程序的元素像神经元一样相互连接。在神经网络上运行的机器学习算法通常被称为深度学习系统,以区别于统计相关等其他方法。
如今,科学家们部署了各种类型的AI来挖掘海量数据,从高吞吐量的DNA和RNA测序到电子病历的大量收集。这些努力展现出AI的广泛应用,并强调了在研究中使用AI的潜力和挑战。
遗传学的新面孔
现在一些将机器学习应用于科学问题的软件开发人员开始为社交媒体公司工作。例如,Facebook自动照片标签功能算法的创造者们,过去几年一直在关注一个略微不同的图像处理问题:从面部特征中识别罕见的遗传疾病。
美国FDNA公司的CEO Dekel Gelbman说:“大约有一半的遗传疾病可以通过非常独特的面部特征进行判断。” 虽然大多数人都能识别唐氏综合症患者的独特特征,但受过专门训练的人类遗传学家能从面部特征找出数千种不太常见的病症。这种类型的诊断依赖于广泛的经验,是很难获得的,因为许多遗传疾病十分罕见。Gelbman说:“一些非常有经验的遗传学家,有时也自称为畸形学家,能够快速地看一眼病人并说,我以前见过类似的病例。”
虽然大多数个体遗传疾病都很罕见,但它们的共同影响是巨大的:据估计,10%的儿童出生时就患有罕见的遗传疾病,其严重程度足以影响他们的生活质量。Gelbman说:“平均来说,一个罕见病患者要等七年半才能得到诊断,这是无法想象的”。他希望将畸形学家的工作自动化能够加快诊断速度。
然而,要做到这一点,FDNA必须克服两个相关的障碍:(1)医生不愿意依赖他们不了解的技术,(2)政府监管机构对医疗诊断的严格标准。两者都在与当前机器学习系统的不可预知性作斗争。Gelbman表示,真的很难相信AI系统,(因为)即使是程序员也很难理解结果的逻辑。开发人员对算法进行训练和测试,直到它给出正确的答案,但是这些答案背后的推理仍然是不可思议的。
为了解决这个问题,Gelbman提倡提高关于如何训练和测试算法的透明性。虽然他们对这项技术的了解在过去一年里有了很大的提高。但FDNA迄今仍未将其应用纳入监管机构的管辖范围,只是清楚地将这些应用标注为提供建议和参考,而非确定的诊断。
如果达尔文是一位计算机科学家
需要更多透明度的不仅仅是医疗诊断工具。美国AI咨询公司Natural Selection的CEO Gary Fogel表示,机器学习中的很多方法都是黑盒方法,当你和生物学家一起工作时,这将成为一个问题,因为他们真的想了解系统是如何工作的,而不仅仅是得到正确的答案。对他们来说,问题就变成了,‘为什么模型会适用于这个特解(particular solution)?’。
Fogel的公司利用机器学习的一种类型构建AI系统,这种机器学习至少在原则上应该对生物学家有吸引力,那就是进化算法。在这种方法中,问题的候选解决方案被视为群体中的个体,而适应度函数决定了它们的质量。该系统选择性地放大高质量的解,抑制或消除低质量的解,直到出现最优解。从分析基因组数据到筛选候选药物分子,再到优化工业流程,Natural Selection已经将这种方法应用于方方面面。然而,正如前面提到的,每个解决方案的内部逻辑可能和复杂的有机体一样难以理解。
该公司通过构建在系统中能够识别显著特征的算法来弥补这一缺陷。Fogel说:“(我们试图找出)哪些特征对疾病或结果很重要,而且试着把这些特征简化成有意义的东西,这样生物学家就能理解这个系统的生物学原理”。
不过,对于一些研究应用程序来说,不透明算法不是问题。当研究人员使用AI作为一种工具来识别可能的线索,并将其与实验数据进行核对时,发现通过算法得到的结果尤其正确。Fogel说:“如果你只是想了解基因组学,也许不需要有一个开放的盒子。如果它仍然准确地预测了microRNA基因的位置,你真的不用关心它为什么正确,只要关心它的确做对就好了。”
尽管如此,即便是希望将AI仅仅用作实验室工具的研究人员,也需要谨慎选择自己的算法。Fogel表示很多人都是这个领域的新手,正在尽可能地获取开源工具。他们没有十分的必要知道如何调整这些算法来解决手头的问题,他们也没有意识到如何表示问题本身很重要。他敦促处于这种情形的科学家向计算机学家寻求帮助,其中许多计算机学家正急于将自己的算法设计技能应用到其他领域。
矢量微积分
苏格University of Glasgow的高级研究员Daniel Streicker将机器学习应用于流行病学中最古老的问题之一:识别病毒载体和宿主。世界上许多最致命的人类病毒都是人畜共患的,大多数时候在动物宿主中繁殖而未被发现,偶尔也会传染给人类。当这些感染通过节肢动物载体在宿主之间传播时,流行病学家可能要花费数十年时间来识别相关的非人类宿主和载体。然而,近年来,研究人员发现,最适合在宿主之间跳跃的RNA病毒,会根据它们主要感染的宿主优化基因组的各种特征。这意味着在病毒的基因组序列中应该有可以提示宿主和载体身份的线索。
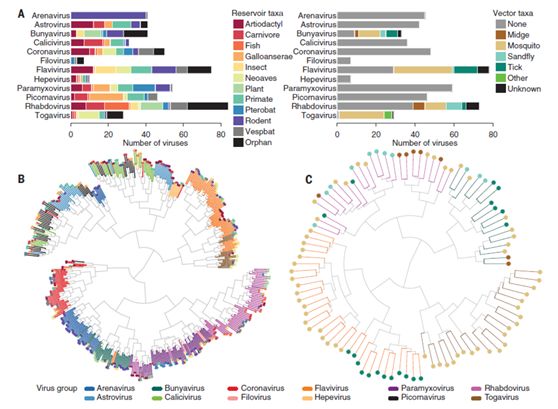
病毒分类群中宿主库和节肢动物媒介关系的分布和层次聚类(Science 2018, 362, 577-580)
作为一名生物学家,Streicker觉得这个想法很诱人,但不知道如何去实现。他说:“我的同事Simon Babayan在我们学院举办了一个非正式研讨会,讨论他正在应用机器学习方法进行研究的各种项目,我突然想到,这可能是解决我所面临的挑战的完美的解决办法”。两人与生物信息学家Richard Orton合作,开始构建搜索病毒宿主和载体的算法(工作发表于Science)。
针对有良好生命特征周期的病毒基因组序列,该团队对他们的机器学习系统进行了训练,使其能够识别出不同序列特征与特定宿主和载体物种之间的相关性。Streicker表示你实际上只是想找到这些特征的加权组合,使你能够有效地将基因组的特征映射到宿主身上。”
在培训阶段结束后,他们在另一组已知宿主的病毒上进行了测试,以验证其可靠性。最后,他们给系统提供了一组对病因知之甚少的病毒基因组,并让系统预测它们的传播模式。
许多结果证实了现有的理论,但该系统也展现出一些令人惊讶的地方。例如,病毒学家认为克里米亚-刚果出血热病毒主要通过蜱虫媒介传播,但计算机预测,家畜之间的直接传播也可能是感染的主要途径。该算法还预测,除了蝙蝠,非人灵长类动物也可能是埃博拉病毒的重要宿主。
Streicker说:“我们正在考虑如何使用类似的方法来尝试预测人类是否会被病毒感染,这显然是一个与监测和公共卫生非常相关的问题,因为现在有太多的病毒被发现。” 虽然他们最初的工作只专注于单链RNA病毒,但他们也希望将该项目扩大到包括其他类型的病毒基因组。
做所有的研究
虽然基因组序列已经成为算法驱动研究的一个主要焦点,但其他大规模数据集也已经成熟,并可以用于机器学习。例如,在过去的几年里,哥伦比亚大学欧文医学中心(CUIMC)的研究人员一直在使用各种计算方法来分析海量的电子医疗记录,并研究生物医学文献本身。
人们注意到不同的研究得出了看似有效的设计,却得出了截然相反的结论。例如,关于抗抑郁药物增加还是降低自杀风险,取决于人们相信哪一项研究。CUIMC生物医学信息学主席George Hripcsak表示,没有两组人选择相同的变量进行校正,然后他们坚持认为,你必须选择完全正确的变量。
与此相关的一个问题是,期刊倾向于发表显示积极结果的论文,而这些论文往往基于一种武断的统计标准。Hripcsak自己对文献的分析表明,偏差显著时,发表的概率值(统计意义的度量)急剧下降到0.05。因此,研究人员面临着巨大的压力,他们必须选择能够产生可发表概率值的变量和统计技术,这可能会使他们的分析产生误差。
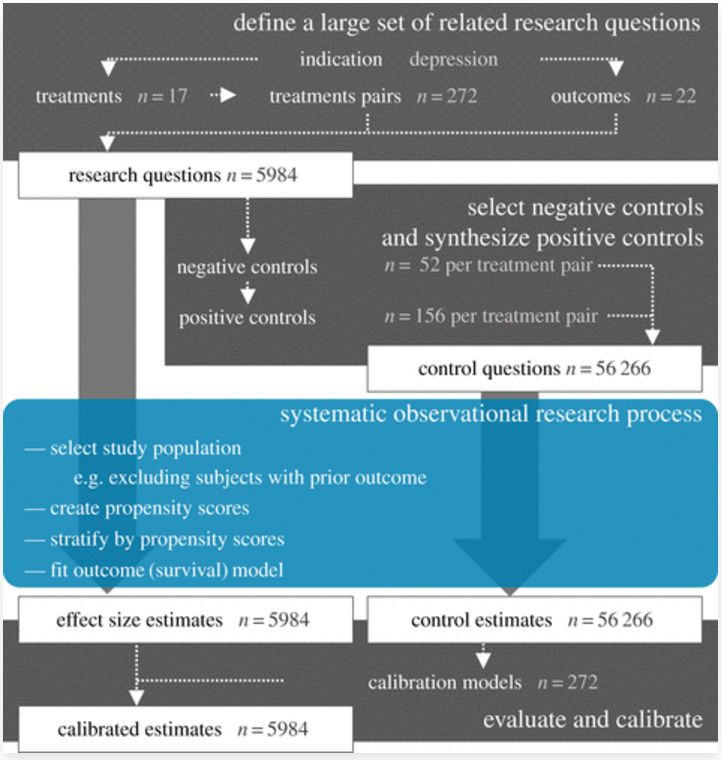
高通量观察性研究设计与经验校准,应用于抑郁症治疗的比较,并将此设计应用于四个大型保险索赔数据库(Philos. Trans. Royal Soc. A 376, 20170356 (2018))
为了解决这个问题,Hripcsak和同事们把研究设计的工作交给了计算机。在最近的一个项目中,他们利用了包含数亿份患者个人医疗记录的多个数据库,使用一种算法设计并同时对数据执行所有合理的观察性研究。针对抑郁症,该算法确定了6000个潜在的研究假设和5.5万多个控制假设,涵盖17个治疗方案、272对联合治疗方案和22个结果。该算法在一台功能强大的计算机上运行了大约一个月并预估了5,984种不同治疗的效果。每一项研究结果都符合目前在顶级同行评审期刊上发表论文的方法标准。而且,研究小组的结果分布中不只有积极的一面,也有消极的部分,这是令人欣慰的,表明他们避免了通常的发表误差。
不过,消除人类的偏见并不能自动解决问题。和该领域的其他人一样,他担心许多机器学习算法的不透明性可能掩盖令人不安的错误。例如,Hripcsak说:“经济因素或其他因素可能使某些种族群体在治疗上做得不好,然后系统建议不给他们治疗,而实际上这与他们的种族无关”。
尽管有这些障碍,但他和该领域的其他人对AI在研究方面的未来持乐观态度。Fogel说:“我看到一场革命正在发生,这很好”。
原文链接:
https://science.sciencemag.org/content/365/6459/1333.2
来源:Polymer-science 高分子科学前沿
原文链接:https://mp.weixin.qq.com/s?__biz=MzA5NjM5NzA5OA==&mid=2651722814&idx=5&sn=5ea258054fc2460a3653c91da707be56&chksm=8b4a067bbc3d8f6d334f5b34547c3148847144a5e005e97acd90df4821743adb55c07c14f918&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn

【WRC 大咖观点】John Hennessy《运用机器学习和机器人技术改善我们的生活》
《口腔种植机器人临床应用继续教育学习班》通知

李德毅:未来汽车应是会学习的轮式机器人
一个机器人一次性向所有机器人学习?全球34个实验室联合研究




美国伯克利机器人学习实验室发布可叠衣服可泡咖啡的机器人
《口腔种植机器人临床应用继续教育学习班》通知
1800余名选手参加南通市教育机器人竞赛


顺德区数控机械创新应用示范工程及自动化技术交流会召开
“制造业转型升级”论坛在深圳举行

【WRC • 风向】新算法瞄准机器人“相互”避让


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号