

科技工作者之家
加好友
科技工作者之家 2021-08-26
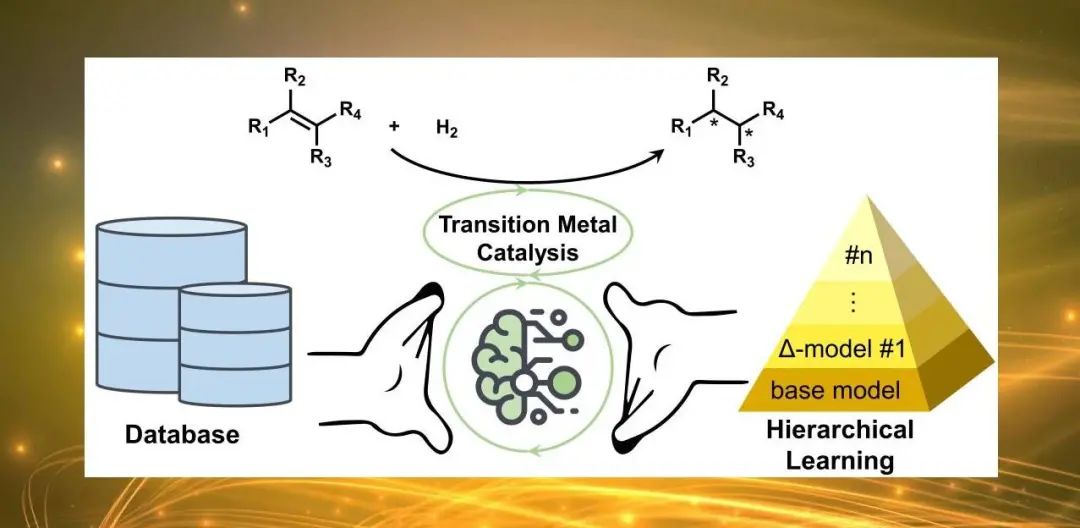
不对称催化合成是手性分子精准构筑的核心策略,在学术研究和工业应用中具有重要的价值。尽管机制研究、计算模拟、构效关系以及高通量实验等手段为反应优化提供了有力的帮助,目前不对称催化体系的筛选仍依赖于经验认识,难以满足社会发展对于不对称催化合成日新月异的要求。
近日,浙江大学化学系洪鑫课题组从烯烃不对称氢化反应近20年的研究论文中收集了超过12000条反应数据,构建了开放获取的标准化数据库(asymcatml.net)。基于烯烃不对称氢化的大数据,作者发展了层级学习的新策略,使得机器学习模型能够模仿人类化学家去关联文献的海量数据与目标转化的少量筛选数据,为不对称催化反应优化中的小样本学习问题提供了人工智能的解决方案。
该标准化数据库详细地记录了超过300篇文献中12619条烯烃不对称氢化反应数据,数据涉及2754种烯烃底物与1686种手性催化剂,存储了所有涉及化合物的SMILES字符串、xTB优化的分子结构以及不对称氢化的反应条件与反应表现等。该数据库的构建为近二十年烯烃不对称氢化反应的研究提供大数据的视角,也为不对称催化的智能建模提供了数据基础。
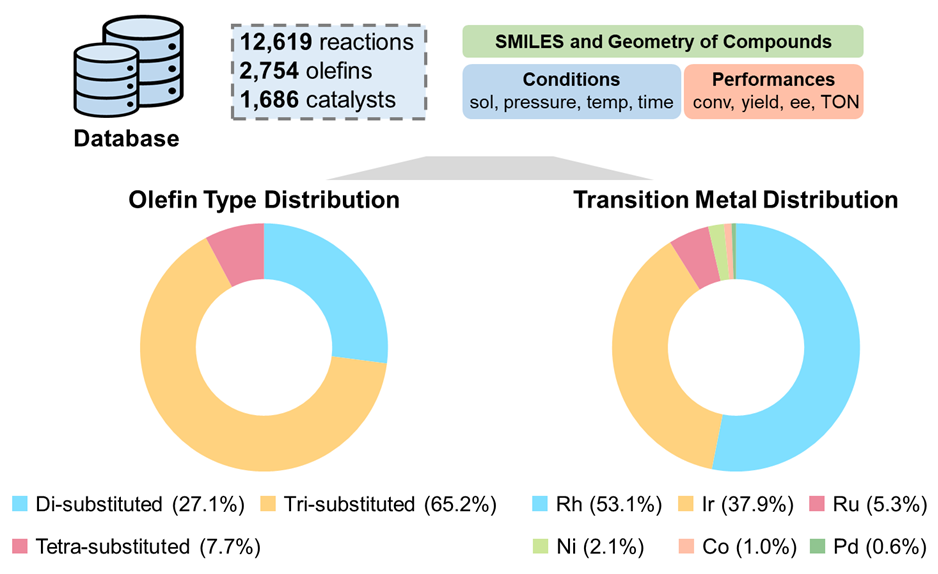
(图片来源:Angew. Chem. Int. Ed.)
为了实现文献大数据与目标转化小样本的有效结合,作者发展了层级学习的建模新方法。基于目标烯烃的结构,通过相似性指征抽取数据库中的相关数据。以关联性较弱的大数据训练基模型,进而运用关联性较强的小样本数据修正基模型的预测误差,取得了回归表现的显著提高。该集成模型的化学原理是通过基模型来掌握催化构效关系的基本规律,再利用目标转化的小样本数据来学习特定化学空间中基本构效关系的微扰变化。该策略可结合多种结构相似性的衡量标准,在若干目标烯烃的测试中均表现了明显的优势。
(图片来源:Angew. Chem. Int. Ed.)
在该工作中,洪鑫课题组构建了烯烃不对称氢化反应的标准化数据库,为数据驱动的不对称催化转化智能建模提供数据支撑,所发展的层级学习策略能够有效地根据化学相关性关联和使用反应数据,为合成转化中的反应优化提供了有效的建模方法。
来源: CBG资讯
原文链接:http://mp.weixin.qq.com/s?__biz=MzI4ODQ0NjUwMg==&mid=2247535588&idx=3&sn=5c4779e1d4d01358a6e18db60440c511
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn
MemTrax机器学习分类模型可以有效应用于认知障碍患者的诊断支持

【前沿】DeepMind新研究:三招解决机器学习模型debug难题
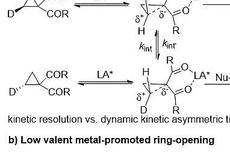
Donor-Acceptor环丙烷参与的不对称催化反应进展
机器学习模型助力探寻新冠病毒新变种

机器学习模型可识别乳房病变风险

如何流水线般的构建硅中心手性?试试串联不对称碳氢硅化/烯烃硅氢化反应
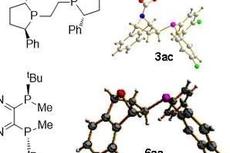
【有机】烯烃的不对称膦氢化反应:Azaphos和Oxaphos配体的设计与合成

最新研究:机器学习模型可识别肿瘤恶液质

图上的机器学习:模型和综合分类法

利用机器学习成功建立:高度精确的分子水模型!
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号