科技工作者之家
科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
科技工作者之家 2019-06-12
来源:学术头条
虽然现在深度学习几乎一统天下,但回顾一下经典还是很有意思的。LSA已经成为经典的经典,UCB的Thomas Hofmann(现在已经到了Google)提出的PLSA,普林斯顿的David Blei提出的LDA,其实在很多应用中还很有效的。
在话题提取问题中,一类经典的模型就是话题模型。总的来说,话题模型的目标是在大量的文档中自动发现隐含的主题结构信息。在本文中,我们将主要介绍以下几种常见的主题模型:(1)潜在语义分析(LSA)模型;(2)概率潜在语义分析(PLSA)模型;(3)潜在狄利克雷分配(LDA)模型。
接下来我们将一一介绍这些模型,并阐明这些模型的相对优缺点。
潜在语义分析(LSA)模型
在潜在语义分析(LSA)模型[1] 首先给出了这样一个 ‘‘分布式假设”[2]:一个 单词的属性是由它所处的环境刻画的。这也就意味着如果两个单词在含义上比较接近,那么它们也会出现在相似的文本中,也就是说具有相似的上下文。
简单地说,LSA首先构建了这样一个 ‘‘单词-文档’’ 矩阵:矩阵的每一行表示一个单词, 矩阵的每一列表示一个文章,第 i 行第 j 列的值表示第 i 个单词在第 j 个段落里面出现了几次或者表示该单词的 tf-idf 值[3,4] 等等。LSA模型在构建好了单词-文档矩阵之后,出于以下几种可能的原因,我们会使用奇异值分解(Singular Value Decomposition,SVD)[5]的方法来寻找该矩阵的一个低阶近似:
原始的单词-文档矩阵过于庞大而会消耗过多的计算资源。在这种情况下,近 似的低阶矩阵可以被解释为原始矩阵的一个 ‘‘近似’’。
原始的单词-文档矩阵往往包含着很多噪音,也就是说并不是里面的任何一个信息都是有用的。在这种情况下,求近似的矩阵的过程可以看成对原来的矩阵进行 ‘‘降噪’’。
原始的单词-文档矩阵相对于 ‘‘真实的’’ 单词-文档矩阵而言过于稀疏。所谓真实的矩阵,就是指将世界上所有出现的单词和文档都考虑在内得到的矩阵,而这显然是不可能的。我们只能通过分析一部分数据来得到真实矩阵的一种近似。在这种情况下,近似的矩阵可以看成是原始矩阵的一种 ‘‘精简’’ 版本。
概率潜在语义分析(PLSA)模型
概率潜在语义分析(PLSA)模型[6] 其实是为了克服潜在语义分析(LSA)模型存在的一些缺点而被提出的。LSA 的一个根本问题在于,尽管我们可以把 Uk 和 Vk 的每一列都看成是一个话题,但是由于每一列的值都可以看成是几乎没有限制的实数值,因此我们无法去进一步解释这些值到底是什么意思,也更无法从概率的角度来理解这个模型。而寻求概率意义上的解释则是贝叶斯推断的核心思想之 一。
PLSA模型则通过一个生成模型来为LSA赋予了概率意义上的解释。该模型假设,每一篇文档都包含一系列可能的潜在话题,文档中的每一个单词都不是凭空产生的,而是在这些潜在的话题的指引下通过一定的概率生成的。
在 PLSA 模型里面,话题其实是一种单词上的概率分布,每一个话题都代表着一个不同的单词上的概率分布,而每个文档又可以看成是话题上的概率分布。每篇文档就是通过这样一个两层的概率分布生成的,这也正是PLSA 提出的生成模型的核心思想。
PLSA 通过下面这个式子对 d 和 w 的联合分布进行了建模:
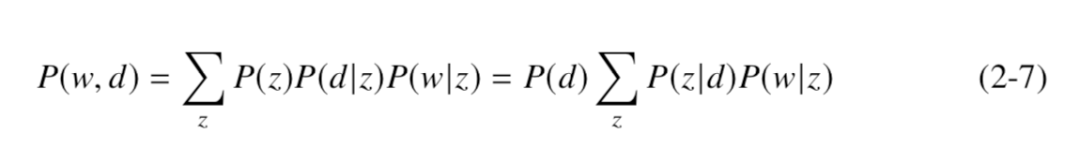
该模型中的 z 的数量是需要事先给定的一个超参数。需要注意的是,上面这 个式子里面给出了 P(w, d) 的两种表达方式,在前一个式子里,d 和 w 都是在给定z 的前提下通过条件概率生成出来的,它们的生成方式是相似的,因此是 ‘‘对称’’ 的;在后一个式子里,首先给定d,然后根据 P(z|d) 生成可能的话题 z,然后再根据 P(w|z) 生成可能的单词 w,由于在这个式子里面单词和文档的生成并不相似, 所以是 ‘‘非对称’’ 的。
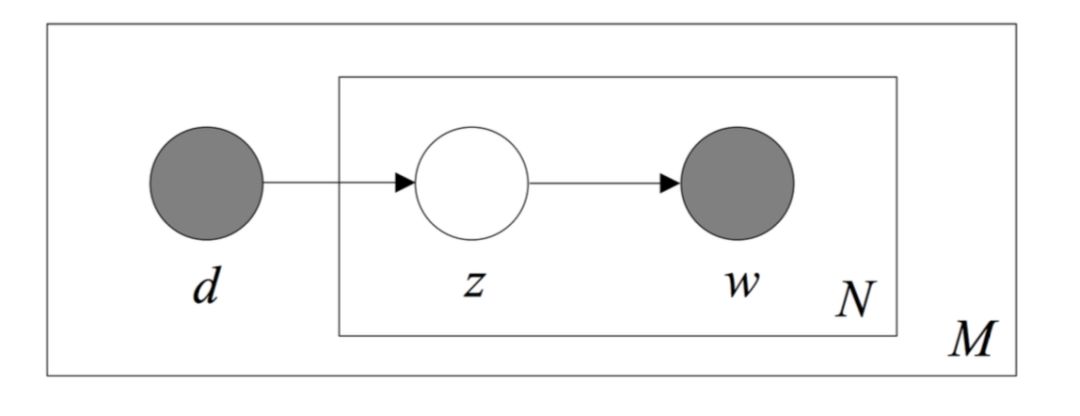
上图给出了 PLSA 模型中非对称形式的 Plate Notation表示法。其中 d 表示 一篇文档,z 表示由文档生成的一个话题,w 表示由话题生成的一个单词。在这个模型中,d 和 w 是已经观测到的变量,而 z 是未知的变量(代表潜在的话题)。
容易发现,对于一个新的文档而言,我们无法得知它对应的 P(d) 究竟是什么, 因此尽管 PLSA 模型在给定的文档上是一个生成模型,它却无法生成新的未知的文档。该模型的另外的一个问题在于,随着文档数量的增加,P(z|d) 的参数也会随着线性增加,这就导致无论有多少训练数据,都容易导致模型的过拟合问题。这两点成为了限制 PLSA 模型被更加广泛使用的两大缺陷。 潜在狄利克雷分配(LDA)模型
为了解决 PLSA 模型中出现的主要问题,潜在狄利克雷分配(LDA)模型被 Blei 等人提出[7],这个模型也成为了主题模型这个研究领域内应用最为广泛的模 型。从根本上来讲,LDA 模型是在 PLSA 的模型的基础上引入了参数的先验分布这个概念。
从上一节我们可以看到,在 PLSA 这个模型里,对于一个未知的新文档 d,我们对于 P(d) 一无所知,而这个其实是不符合人的经验的。或者说,它没有去使用本来可以用到的信息,而这部分信息就是 LDA 中所谓的先验信息。
具体来说,在 LDA 中,首先每一个文档都被看成跟有限个给定话题中的每一个存在着或多或少的关联性,而这种关联性则是用话题上的概率分布来刻画的, 这一点与 PLSA 其实是一致的。但是在 LDA 模型中,每个文档关于话题的概率分布都被赋予了一个先验分布,这个先验一般是用稀疏形式的狄利克雷分布表示的。 这种稀疏形式的狄利克雷先验可以看成是编码了人类的这样一种先验知识:一般而言,一篇文章的主题更有可能是集中于少数几个话题上,而很少说在单独一篇文章内同时在很多话题上都有所涉猎并且没有明显的重点。
此外,LDA 模型还对一个话题在所有单词上的概率分布也赋予了一个稀疏形式的狄利克雷先验,它的直观解释也是类似的:在一个单独的话题中,多数情况是少部分(跟这个话题高度相关的)词出现的频率会很高,而其他的词出现的频率则明显较低。这样两种先验使得 LDA 模型能够比 PLSA 更好地刻画文档-话题-单词这三者的关系。
事实上,从 PLSA 的结果上来看,它实际上相当于把 LDA 模型中的先验分布转变为均匀分布,然后对所要求的参数求最大后验估计(在先验是均匀分布的前提下,这也等价于求参数的最大似然估计)[8],而这也正反映出了一个较为合理的先验对于建模是非常重要的。
而好的先验其实源于对于现象的准确深刻的洞察。
参考文献:
[1] Hofmann T. Probabilistic latent semantic analysis[C]//Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence. [S.l.]: Morgan Kaufmann Publishers Inc., 1999: 289–296.
[2] Firth J R. A synopsis of linguistic theory, 1930-1955[J]. Studies in linguistic analysis, 1957.
[3] Salton G, Buckley C. Term-weighting approaches in automatic text retrieval[J]. Information processing & management, 1988, 24(5): 513–523.
[4] Ramos J, et al. Using tf-idf to determine word relevance in document queries[C]//Proceedings of the first instructional conference on machine learning: volume 242. [S.l.: s.n.], 2003: 133–142.
[5] Kalman D. A singularly valuable decomposition: the svd of a matrix[J]. The college mathematics journal, 1996, 27(1): 2–23.
[6] Deerwester S, Dumais S T, Furnas G W, et al. Indexing by latent semantic analysis[J]. Journal of the American society for information science, 1990, 41(6): 391.
[7] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993–1022.
[8] GirolamiM,KabánA.On an equivalence between plsi and lda[C]//Proceedings of the 26 th annual international ACM SIGIR conference on Research and development in informaion retrieval. [S.l.]: ACM, 2003: 433–434.
来源:SciTouTiao 学术头条
原文链接:http://mp.weixin.qq.com/s?__biz=MzU1MTkwNzIyOQ==&mid=2247489183&idx=1&sn=b9d0ef23b1f1e84bdefcb6e04da194f6&chksm=fb8b6c6dccfce57bf45f0bdd95bfbaae7222a3eed9e5c5ba9a5b4029afb1afd6a8df39e3ac6a&scene=27#wechat_redirect
版权声明:除非特别注明,本站所载内容来源于互联网、微信公众号等公开渠道,不代表本站观点,仅供参考、交流、公益传播之目的。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。
电话:(010)86409582
邮箱:kejie@scimall.org.cn

基于基因互作网络的突变图谱非负矩阵分解模型(NBS)揭示肿瘤亚型

主流听觉理论被颠覆,大脑可并行处理声音和单词

考研英语首轮复习之重:单词、语法怎么学更高效?

俄研究单词如何在大脑中储存

轻轻一电,恢复记忆!这些年轻人就这样提高了记单词的成绩……

人工智能专家王笛为你详解基于矩阵分解的哈希跨媒体检索方法

最新研究发现狗能够明白单词代表的物体

意大利人每讲100个单词要做22次手势

22年考研:背单词注意6大致命误区

“7张纸,搞定5500考研单词,你也可以!”


科技工作者之家APP是专注科技人才,知识分享与人才交流的服务平台。
 微信
微信
 京公网安备11010202008424号
京公网安备11010202008424号